

AdamT
-
Posts
37 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Everything posted by AdamT
-
Hope I was able to help you out. Here is what my setup looks like with 5 HDD and 2 M.2 SSD cache drives. Also, a comparison of drive benchmarks I did when I got a new M.2 SSD drive for my PC, it's comparing my old SSD drive, my new SSD drive and the HDD the new SSD drive is replacing. All three of those charts are on the same scale and I added vertical lines manually approximately where they should go for SATA2 (Green), SATA3 (Yellow), and M.2 (PCIe 3.0 x4, Purple). this type of thing is why snarky people like me call regular HDD "spinning rust" :-).
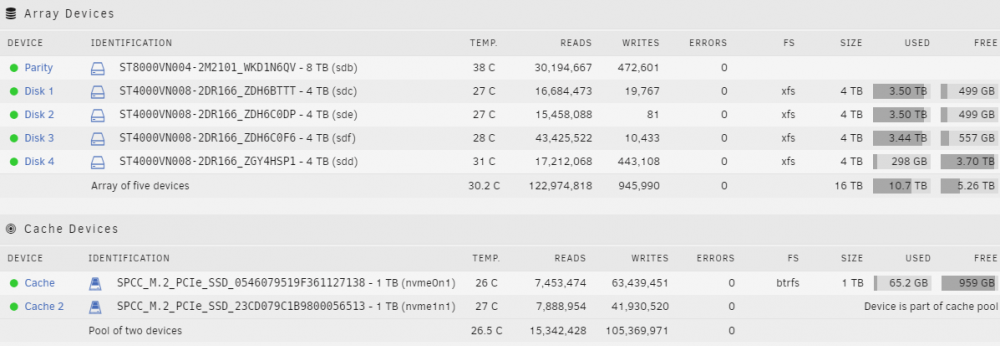
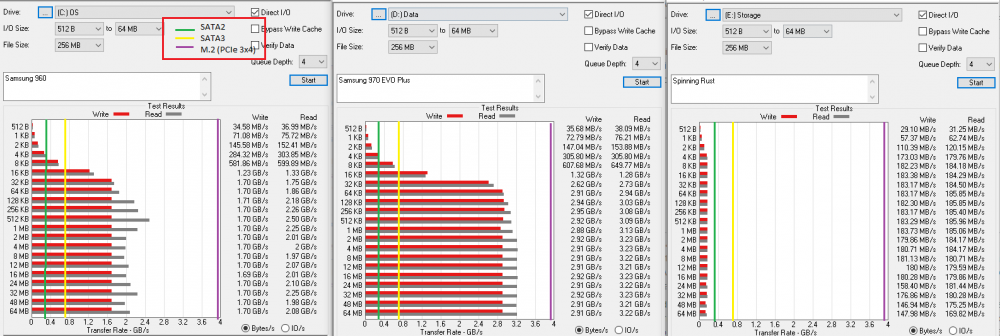
-
Yes, I think you are right. Unless you want to populate your drive cage with SSD drives (or larger regular drives), upgrading your backplane won't help your speeds. What will help speeds is if you get a single smaller SSD (M.2 is best) and make it your cache drive. If you plan on using Docker or VMs, I would suggest getting two cache drives and putting them in a cache pool. This way, any data used for Docker or VMs can reside on the fast SSD and your regular drives can sleep and you still have data protection.
-
Yeah, those drives (pdf) only use 147MB/s, the interface on the drive is a SATA3 (6Gb/s or 600MB/s) and it's hooked to something that is telling the system it can only handle SATA2 (300MB/s). But that's just saying "oh yeah, you can talk at 300 MB/s, roger" which doesn't mean that much can ever come out. it's kind of like saying that you have a 6cm pipe connecting your house to the water but as soon as the pipe comes into the house it turns into 2cm pipe; making the 6cm pipe 12cm isn't going to make the water in the house run faster.
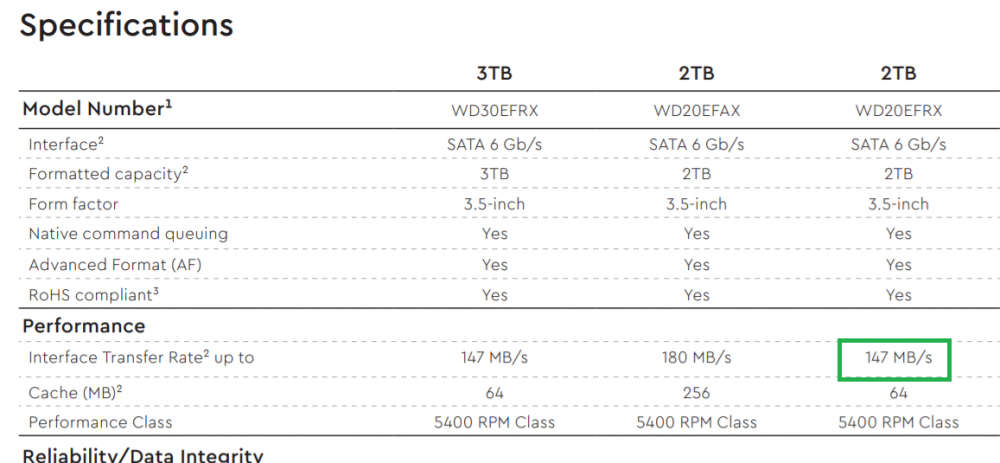
-
What are you using for hard drives? SSD or spinning rust? my understanding is that non-ssd drives only go up to about 150 MB/s (SATA1 is 150 MB/s, SATA2 is 300 MB/s), so you shouldn't see any actual difference. I needed to buy the non-expanded one because the expanded one did not recognize my 4TB drives. You may be ok with what you have now.
-
My reading of the ebay ad you showed is that it should have worked. It should have had 6 SATA ports on it which you would have hooked to a card or motherboard (i.e. "Requires six free SAS or SATA ports"). You received the one you sent a picture of yesterday? It only has two SAS/SATA ports on it.
-
Here is a link to the spare parts manual (pdf) for the server I think you have. It looks like there are four backplane options (2x 4 drive and 2x 6 drive). The two options are 1 for an expander and the other for no expander. So, if you want SATA3, you'll want the opposite of the one you have now (sounds like the one you used to have that was broken). Good luck. I ended up scrapping my build because my problem was the LSI 9207-8i Controller (the only new thing besides the drives). I kept assuming the old hardware from ebay was the problem but it turned out to be the new stuff 😞
-
Actually, it turns out it may just be that "half" of the drive controller. after I started the rebuild, drive 2 started getting crc errors. I moved drive 2 to the new cable when I moved drive 3 off. So I canceled the rebuild and moved all the drives to the apparently working half of the controller. No problems yet with the 2nd try at rebuilding and it's over 50% already. I guess I need to by another new drive controller
-
Thanks guys, I did a long smart test on both drives overnight and they both passed. I moved my cache drive (on a pcie card) as far away from the drive controller card as possible and put a small extra fan on that area. Finally it looks like the two drives in question were on the same miniSAS cable, so I replaced that. further, I moved one of those two drives onto the other "side" of the drive controller so they do not share a cable anymore (even though it would be the new cable). I'm doing a rebuild now. Fingers crossed! Luckily, I have backups of the important stuff... and my old unraid setup with old drives which I just replaced ~1 month ago.
-
Hello, I noticed today that my array went into degraded mode. I dug into the diagnostics info (attached), to find a lot of sd 1:0:x:0: Power-on or device reset occurred messages as well as disk0 read errors and disk3 read/write errors. Most of the device reset messages are for sd 1:0:1:0 and the rest are for sd 1:0:2:0. I have taken the array offline. A short smart test on disk0 and disk3 shows a pass but I see the UDMA CRC error count is > 0 for both of these drives (and not the others). All of the drives and the controller are new (~1 month old). My initial guess (hope?) is there is a cable issue but I was wondering if there is anything else I can do *before I power off the machine* and lose state info. If not, I'm hoping to find the same cable hooking to the two drives in question and I can just replace it and it will work fine. But I've never had a failure in my UnRAID array so I want to make sure I'm covering all my bases. Thanks, Adam unraid-diagnostics-20190807-1608.zip
-
I ended up doing this as well and it's worked out quite well. Here is what I did (and how much it cost) The base machine was the same Intel SC5650HCBRP Xeon E5620 Quad-Core 2.4GHz 6GB Dual GbLAN ($160 ebay). I initially got 2 Seagate IronWolf 4TB NAS Internal Hard Drive HDD ($100/ea amazon) and a LSI Logic SAS 9207-8i Storage Controller ($80 amazon) to see if it would work. The main reason I went with this case was the 6 bay hot swap cage so I really wanted the LSI to work with the cage backplane card. Unfortunately, the backplane that came with the cage had only two SATA ports and its own "smarts" which didn't work with my drives (direct connect to the LSI worked, but not through the cage backplane... 2TB limit, maybe?). However, I found that there was another backplane option with 6 SATA ports that I hoped was a passthrough with no smarts. I found an Intel D22808-203 6 hard drive sata backplane ($44 ebay) so I went with it and it worked! So, for me, a fully working bare minimum server was +$160 - Intel Server +$80 - LSI 9207-8i Controller +$44 - D22808-203 Backplane ---------- =$284 (with no drives) +$200 - 2x 4TB HDD ---------- =$484 (fully functional, but minimal 4TB Storage; 1 Parity) At that point, I got a few more HDDs and a Silicon Power 1TB NVMe PCIe Gen3x4 M.2 2280 ($110 amazon) which needed a QNINE NVME PCIe Adapter, M.2 NVME SSD to PCI Express 3.0 Host Controller Expansion Card ($15 amazon). That adds some extra cost =$484 (minimal config) +$200 - 2x 4TB HDD +$110 - 1TB NVMe PCIe +$15 - NVMe PCIe Expansion Card ---------- =$809 (6GB RAM; 12TB Storage; 1 Parity; 1TB Cache) Then I got silly. I fired up some dockers and noticed the 6GB RAM was lacking, but I had 9 free RAM slots. I found some cheap 10x 2GB RAM ($50 ebay) and another Intel SLBV4 Xeon E5620 Quad-Core 2.40GHz CPU ($7! ebay) which needed a BXSTS100A Intel Thermal Solution FAN/Heatsink ($42). =$809 (6GB RAM; 12TB Storage; 1 Parity; 1TB Cache) +$50 - 10x 2GB RAM (could only use 9 though) +$7 - Xeon E5620 CPU (technically I bought 2 for $7 in case one didn't work... $3.50 each!) +42 - Fan/Heatsink for the new CPU ---------- =$908 (24GB RAM; 8 Xeon Cores w/HT; 12TB Storage; 1 Parity; 1TB Cache) I think it worked out pretty well as the $400 HDD and $110 NVMe would have been the same cost for whatever other solution I would have built. So I ended up paying $398 for an 8 core, 24 GB RAM machine WITH a 6 drive hot swap cage. Thanks for the idea and I hope this helps anyone else trying this 🙂
-
Huh, I'm stumped. Send me the mrtg.cfg file as a PM and I'll have a look.
-
Great! Glad it's working :-)
-
Ok, that's good. I wonder if your mrtg.cfg has formatting issues? The blocks that you're having problems with have extra long lines, can you make sure that all the lines that start with Target[...]: haven't been accidentally split into two lines? Like this one, it should all be one line: Target[server.mempercentused]: 100 - ( ( memAvailReal.0&memAvailReal.0:public@localhost + memBuffer.0&memBuffer.0:public@localhost + memCached.0&memCached.0:public@localhost ) * 100 / ( memTotalReal.0&memTotalReal.0:public@localhost ) )
-
Ah, check your mrtg.cfg file, I suspect you have something wrong with one of the PageTop lines, perhaps there is no newline at the end or something? If you want, PM me your exact config file and I'll have a look Target[sda.temp]: `smartctl -n standby -A /dev/sda | egrep "Temp|exit" | perl -pe '$_=substr($_,87,2);$_=0 if($_ eq "");$_="$_\n$_\n0\n0\n";'` Title[sda.temp]: /dev/sda Temperature PageTop[sda.temp]: <h1>/dev/sda Temperature (Celsius)</h1> MaxBytes[sda.temp]: 60 AbsMax[sda.temp]: 100 Unscaled[sda.temp]: ymwd ShortLegend[sda.temp]: C YLegend[sda.temp]: Temperature (C) Legend1[sda.temp]: /dev/sda Temperature LegendI[sda.temp]: sda Temp LegendO[sda.temp]: sda Temp Options[sda.temp]: integer, gauge, nopercent, growright, unknaszero
-
not sure what you mean by "the config text on the webpage" it's more complicated than usual because unRAID is in a RAMdisk and boots off of a flash drive. Add a line like this to the end of your /boot/config/go file (this is all one line) (crontab -l | grep -v mrtg-traffic-sum; echo "05 01 01 * * env LANG=C /usr/bin/mrtg-traffic-sum --email=me@youraddress --range=previous --units=GB /boot/config/mrtg.cfg") | crontab - the format of a crontab line is * * * * * command to be executed ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ??? day of week (0 - 7) (0 or 7 is Sun, or use names) ? ? ? ????? month (1 - 12) ? ? ??????? day of month (1 - 31) ? ????????? hour (0 - 23) ??????????? min (0 - 59) so, in my example (05 01 01 * *), that would mean that at 01:05 on the first of every month it would run the command (env LANG=C /usr/bin/mrtg-traffic-sum --email=me@youraddress --range=previous --units=GB /boot/config/mrtg.cfg). The rest of that line is adding the line into the crontab. after that you would either have to copy/paste the command into the command line (to execute it for the current session) or just reboot the unRAID. after you do that, you can test to see if it worked by typing crontab -l and looking for the line in the output. HTH
-
@generalz and @JarDo: I would try to see if you can access the SNMP variables outside of MRTG. Using SNMPWalk from the command line: root@unRAID:~# /usr/bin/snmpwalk -v1 -c public localhost memTotalReal.0 UCD-SNMP-MIB::memTotalReal.0 = INTEGER: 4084496 kB root@unRAID:~# /usr/bin/snmpwalk -v1 -c public localhost memCached.0 UCD-SNMP-MIB::memCached.0 = INTEGER: 3619136 kB root@unRAID:~# /usr/bin/snmpwalk -v1 -c public localhost ssCpuRawSystem.0 UCD-SNMP-MIB::ssCpuRawSystem.0 = Counter32: 456891 If that doesn't work, MRTG wouldn't show those variables.
-
Hi, yeah you could put another drive in, but then you would still always have one drive spinning... saving you a net 1 drive spinning (the parity drive wouldn't be able to spin down either if you write to the array all the time). I'm not sure that the humble usb flash drive has any wear-leveling like ssd drives are supposed to. USB flash drives are usually rated for 10,000 - 100,000 cycles (depending on the technology), so figuring worst case: 10,000 cycles over the same exact spots (probably not very likely, even without wear-leveling) at updates every 5 minutes would give about a month lifespan (10,000 write cycles / 12 five minute intervals in an hour / 24 hours in a day = 34.7 days). I had tossed around the idea of putting a tiny ssd drive in my box (newegg has a 16 GB Kingston SSD for $40) for both MRTG and other stuff (I have a weather station that I want to move the monitoring off of a Mac Mini to the unRAID box). If you have an extra drive kicking around, that's probably the best bet if you want your array to spin down. If you don't have an extra drive kicking around and want to spend the money, I would buy the tiny SSD (nothing to spin up/down and wear-leveling should make it last a very long time). USB flash drive is probably the worst bet. Although, there shouldn't be any issue writing to the array (other than the no spinning down). Of course, that's only my $0.02, anybody else have any experience in the matter?
-
Hmm, I would guess that either you have disk usage set up for a disk that doesn't exist or your array isn't mounted or you're attempting to track disk usage without having SNMP know what disks you want to track. Either way, double check the section in /boot/config/mrtg.cfg that deals with disk usage and /boot/config/snmpd.conf. snmpd.conf should have lines like rocommunity public syslocation Here syscontact [email protected] disk /mnt/disk1 disk /mnt/disk2 disk /mnt/disk3 ... in it. if you don't have any disk lines (or no /boot/config/snmpd.conf file at all), you probably are running an older version of the MRTG install. re-copy the http://ruinedkingdoms.com/unRAID/mrtg-unmenu-package.conf file, delete snmpd.conf (if present), and re-install the MRTG package. The "dskPercent.1 dskPercent.2" in your error message means MRTG can't find information about the 1st and 2nd "disk" lines in the snmpd.conf file. Hope that helps.
-
Glad it's helping you out :-) Overhead for MRTG and all the plots but temperature is negligible. Getting the drive temps via smartctl takes a few seconds per drive so if you've got a pile of drives, it could take a while. I'm not sure if this is really overhead (using up mem/cpu) or just the time it takes for the drives to spit out data. I checked top while manually getting SMART data, and it was negligible CPU (0.3% for only part of the time it took to get data) and Mem (less than 0.1% out of 4GB, didn't even show a value in top). I think top was actually using more resources than smartctl :-) I just started using SMART drive data myself, so maybe someone else knows more about that specifically. As a sidenote, I'm switching my personal mrtg.cfg to use by-id device names for the hard drive temp code because Linux changing /dev/sdX for all the drives periodically is kind of annoying. You look like you've got a bunch of drives, so to save your sanity, you might want to do the same :-) It looks like this Target[parity.temp]: `smartctl -n standby -A /dev/disk/by-id/wwn-0x5000cca369cfa7d9 | egrep "Temp|exit" | perl -pe '$_=substr($_,87,2);$_= 0 if($_ eq "");$_="$_\n$_\n0\n0\n";'` Title[parity.temp]: parity Temperature PageTop[parity.temp]: <h1>parity Temperature (Celsius)</h1> MaxBytes[parity.temp]: 60 AbsMax[parity.temp]: 100 Unscaled[parity.temp]: ymwd ShortLegend[parity.temp]: C YLegend[parity.temp]: Temperature © Legend1[parity.temp]: parity Temperature LegendI[parity.temp]: parity Temp LegendO[parity.temp]: parity Temp Options[parity.temp]: integer, gauge, nopercent, growright, unknaszero good luck!
-
Folks, I updated the advanced mrtg.cfg file and the sample chart screenshot. I removed the disk storage monitoring and replaced it with the disk temperature plots. Plus I changed how the memory chart works. Before it was accurate, but misleading in that it showed only memory that had never been used, Linux caches files and programs with memory that isn't currently needed and this didn't show up as "Free" in the older charts. I changed the calculation of "Free" to show how much memory would be available to run programs with (which matches what most people consider "Free") http://ruinedkingdoms.com/unRAID/mrtg_sample_index.png http://ruinedkingdoms.com/unRAID/mrtg.cfg
-
Hi, I checked the MRTG docs (http://oss.oetiker.ch/mrtg/doc/mrtg-reference.en.html) and it seems what you want is to put these lines near the top of your mrtg.cfg file: XSize[_]: 600 YSize[_]: 200 By default, the charts are 100 by 400 pixels. Unfortunately, there are some limitations: "Note: XSize must be between 20 and 600; YSize must be larger than 20"
-
Anyone interested in drive temp monitoring? I've got a bit that queries S.M.A.R.T. to populate the charts. They respect the privacy of drives that are sleeping. Add this line into your mrtg.cfg for each drive you want to monitor (change the blue bits). Target[sda.temp]: `smartctl -n standby -a /dev/sda | egrep "Temp|exit" | perl -pe '$_=substr($_,87,2);$_=0 if($_ eq "");$_="$_\n$_\n0\n0\n";'` Title[sda.temp]: /dev/sda Temperature PageTop[sda.temp]: <h1>/dev/sda Temperature (Celsius)</h1> MaxBytes[sda.temp]: 60 AbsMax[sda.temp]: 100 Unscaled[sda.temp]: ymwd ShortLegend[sda.temp]: C YLegend[sda.temp]: Temperature © Legend1[sda.temp]: /dev/sda Temperature LegendI[sda.temp]: sda Temp LegendO[sda.temp]: sda Temp Options[sda.temp]: integer, gauge, nopercent, growright, unknaszero then run this to update the chart main page (blue is the package default, so if you changed it when you installed the package, change it here) /usr/bin/indexmaker --output=/tmp/mrtg/index.html /boot/config/mrtg.cfg then wait 10-15 minutes for charts to start showing up! Here is a sample
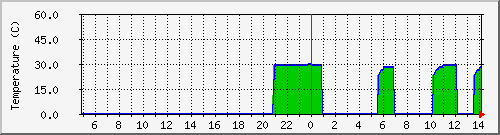
-
Let me see if I can re-compile Slackware's SNMP. If there are too many dependancies, I won't be able to do it (I don't actually have a Slackware dev box setup, I'm compiling stuff on unRAID which doesn't have a lot of packages installed). Ok, I was able to re-compile net-snmp with the required option and I can get stats by both disk (physical drive) and array (drive + parity). That means with this you could track how much was read/written to each disk drive individually or to each "disk share". Unfortunately, it doesn't see user shares at all. I suspect that is because they are really done in software "above" the level that SNMP is monitoring. However, if there is some file somewhere in unRAID that has this information, we can add it to the charts that way. I haven't included this new net-snmp in the mrtg package yet. is anyone interested in by disk read/writes?
-
Thanks, glad it's working for you! Good idea, done.
-
Hmm, I did some digging and it's possible to show bytes read/written to each disk (here's a page on how to do it http://oss.oetiker.ch/mrtg-trac/wiki/Net-SNMP). I'm not sure that shares will have this tracking because it talks about devices. I guess it comes down to how unRAID treats shares under the covers. Unfortunately, the Slackware SNMP package doesn't seem to have support for disk i/o installed, so I can't see if it would work for shares as well. It looks like SNMP needs to be compiled with '--with-mib-modules=ucd-snmp/diskio' but Slackware's isn't: # snmpget -v 1 -c public localhost UCD-SNMP-MIB::versionConfigureOptions.0 UCD-SNMP-MIB::versionConfigureOptions.0 = STRING: '--prefix=/usr' '--libdir=/usr/lib' '--sysconfdir=/etc/snmp' '--mandir=/usr/man' '--enable-ipv6' '--disable-debugging' '--enable-static=no' '--with-libwrap' '--with-perl-modules' '--with-default-snmp-version=3' '[email protected]' '--with-sys-location=unknown' '--with-logfile=/var/log/snmpd.log' '--with-persistent-directory=/var/lib/net-snmp' '--without-rpm' '--program-suffix=' '--program-prefix=' '--build=i486-slackware-linux' 'build_alias=i486-slackware-linux' 'CFLAGS=-O2 -march=i486 -mtune=i686' Let me see if I can re-compile Slackware's SNMP. If there are too many dependancies, I won't be able to do it (I don't actually have a Slackware dev box setup, I'm compiling stuff on unRAID which doesn't have a lot of packages installed).



