

ElectricBadger
-
Posts
107 -
Joined
-
Last visited
ElectricBadger's Achievements
")
Apprentice (3/14)
15
Reputation
-
 Ah yes, the subheadings look the same as the headings. Got it now. Unfortunately, the refresh button didn't do anything, so I guess I'll have to reboot at some point after the parity rebuild. Thanks! Update: it seems to have noticed overnight that the drive had gone, so no need for a reboot. Except there's an unRAID update anyway 😁
Ah yes, the subheadings look the same as the headings. Got it now. Unfortunately, the refresh button didn't do anything, so I guess I'll have to reboot at some point after the parity rebuild. Thanks! Update: it seems to have noticed overnight that the drive had gone, so no need for a reboot. Except there's an unRAID update anyway 😁 -
No, it's not in Unassigned Devices — that's not showing anything. This is what I'm seeing — but Dev 2 (sdq) is no longer physically connected to the server.
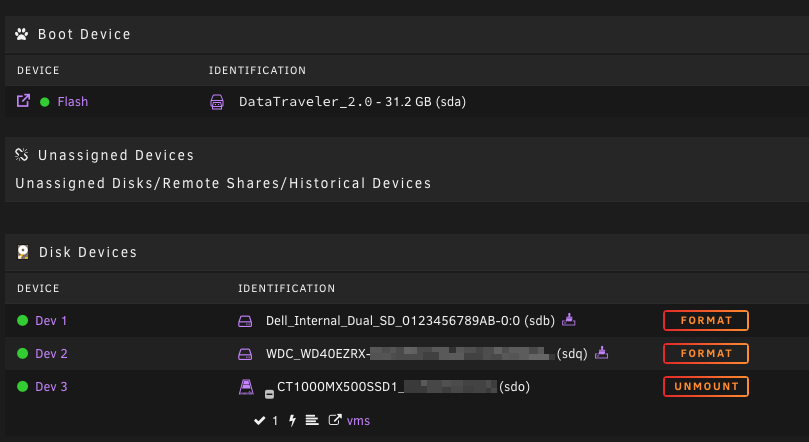
-
I'm using a Dell MD1200 which allows hot-plugging. A failing disk has been removed from the array and is now showing in Disk Devices while the parity rebuilds without it. I've removed the physical drive from its bay, but it's still showing in Disk Devices on the Main screen, with a Format button. How do I get unRAID to refresh its disk list and notice that this drive is no longer attached and should be moved to Historical Devices, without stopping the array or rebooting? There doesn't seem to be a "refresh drive list" button, and clicking on the device name doesn't offer a Remove Device button. Surely, given the amount of hardware that supports hot plugging/unplugging, there must be a way to have unRAID handle this? It's been 30 minutes since I disconnected the disk, and it hasn't even noticed the change yet
-
Thanks — yes, it did finish the parity check successfully; it was about 50% through (and paused during the daytime) when I ran the upgrade — so in progress but paused automatically. UPDATE: While I'm sure I had a notification saying it had finished a couple of days after the reboot, after removing the parity.tuning.restart file I got a notification about half an our later saying the parity check had finished after 9 days, so I guess that gave it a bit of a kick 😁
-
I ran an upgrade to Unraid 6.12.3 while a parity check was running. It paused, and resumed correctly after the upgrade when the resume time came around, and completed successfully after a couple of days. But now, every day at 07:00 (the pause time) I get a Pushover notification saying "Paused. No array operation in progress (0.0% completed)". Is there a way to get rid of this? Would editing the progress.save file be enough to fix it? (Turning "send notifications for pause or resume of increments" off did stop it, but I want those to be on when a check is actually running…) Here's the parity.check.tuning.progress.save file: type|date|time|sbSynced|sbSynced2|sbSyncErrs|sbSyncExit|mdState|mdResync|mdResyncPos|mdResyncSize|mdResyncCorr|mdResyncAction|Description MANUAL|2023 Jul 26 06:34:22|1690349662|1690348691|0|0|0|STARTED|11718885324|129515364|11718885324|1|check P|Manual Correcting Parity-Check| PAUSE|2023 Jul 26 07:00:06|1690351206|1690348691|0|0|0|STARTED|11718885324|334602096|11718885324|1|check P|Manual Correcting Parity-Check| RESUME (MANUAL)|2023 Jul 26 10:24:39|1690363479|1690363219|0|0|0|STARTED|11718885324|369333984|11718885324|1|check P|Manual Correcting Parity-Check| PAUSE|2023 Jul 27 01:00:54|1690416054|1690363219|0|0|0|STARTED|11718885324|6269949784|11718885324|1|check P|Manual Correcting Parity-Check| PAUSE (MANUAL)|2023 Jul 27 01:30:18|1690417818|1690363219|1690416054|0|-4|STARTED|0|6270038284|11718885324|1|check P|Manual Correcting Parity-Check| RESUME (MANUAL)|2023 Jul 27 06:24:22|1690435462|1690435247|0|0|0|STARTED|11718885324|6294077764|11718885324|1|check P|Manual Correcting Parity-Check| PAUSE|2023 Jul 27 07:00:08|1690437608|1690435247|0|0|0|STARTED|11718885324|6526254048|11718885324|1|check P|Manual Correcting Parity-Check| RESUME (MANUAL)|2023 Jul 27 12:30:39|1690457439|1690457240|0|0|0|STARTED|11718885324|6545790780|11718885324|1|check P|Manual Correcting Parity-Check| PAUSE|2023 Jul 28 01:00:48|1690502448|1690457240|0|275|0|STARTED|11718885324|11664698612|11718885324|1|check P|Manual Correcting Parity-Check| PAUSE (MANUAL)|2023 Jul 28 01:12:46|1690503166|1690457240|1690502448|275|-4|STARTED|0|11664770296|11718885324|1|check P|Manual Correcting Parity-Check| RESUME (MANUAL)|2023 Jul 28 06:18:21|1690521501|1690521397|0|275|0|STARTED|11718885324|11674986128|11718885324|1|check P|Manual Correcting Parity-Check| COMPLETED|2023 Jul 28 06:30:16|1690522216|1690521397|1690521948|275|0|STARTED|0|0|11718885324|1|check P|No array operation in progress| And here's the parity.check.tuning.progress: type|date|time|sbSynced|sbSynced2|sbSyncErrs|sbSyncExit|mdState|mdResync|mdResyncPos|mdResyncSize|mdResyncCorr|mdResyncAction|Description SCHEDULED|2023 Aug 21 22:00:07|1692651607|1690521397|1690521948|275|0|STARTED|0|0|11718885324|1|check P|No array operation in progress| PAUSE|2023 Aug 22 07:00:06|1692684006|1692651607|0|0|0|STARTED|11718885324|1975074812|11718885324|0|check P|Scheduled Non-Correcting Parity-Check| RESUME|2023 Aug 22 22:30:08|1692739808|1692651607|1692684006|0|-4|STARTED|0|1975112588|11718885324|0|check P|Scheduled Non-Correcting Parity-Check| PAUSE|2023 Aug 23 01:00:27|1692748827|1692739809|0|0|0|STARTED|11718885324|2939569160|11718885324|0|check P|Scheduled Non-Correcting Parity-Check| PAUSE (MANUAL)|2023 Aug 23 01:12:19|1692749539|1692739809|1692748827|0|-4|STARTED|0|2939681292|11718885324|0|check P|Scheduled Non-Correcting Parity-Check| RESUME|2023 Aug 23 22:30:08|1692826208|1692739809|1692748827|0|-4|STARTED|0|2939681292|11718885324|0|check P|Scheduled Non-Correcting Parity-Check| PAUSE|2023 Aug 24 01:00:35|1692835235|1692826208|0|0|0|STARTED|11718885324|3717129116|11718885324|0|check P|Scheduled Non-Correcting Parity-Check| PAUSE (MANUAL)|2023 Aug 24 01:30:19|1692837019|1692826208|1692835236|0|-4|STARTED|0|3717246472|11718885324|0|check P|Scheduled Non-Correcting Parity-Check| RESUME|2023 Aug 24 22:30:08|1692912608|1692826208|1692835236|0|-4|STARTED|0|3717246472|11718885324|0|check P|Scheduled Non-Correcting Parity-Check| PAUSE|2023 Aug 25 01:00:27|1692921627|1692912609|0|0|0|STARTED|11718885324|4750530368|11718885324|0|check P|Scheduled Non-Correcting Parity-Check| PAUSE (MANUAL)|2023 Aug 25 01:18:23|1692922703|1692912609|1692921628|0|-4|STARTED|0|4750665580|11718885324|0|check P|Scheduled Non-Correcting Parity-Check| RESUME|2023 Aug 25 22:30:07|1692999007|1692912609|1692921628|0|-4|STARTED|0|4750665580|11718885324|0|check P|Scheduled Non-Correcting Parity-Check| PAUSE|2023 Aug 26 01:00:25|1693008025|1692999008|0|0|0|STARTED|11718885324|5863042816|11718885324|0|check P|Scheduled Non-Correcting Parity-Check| PAUSE (MANUAL)|2023 Aug 26 01:12:17|1693008737|1692999008|1693008026|0|-4|STARTED|0|5863140880|11718885324|0|check P|Scheduled Non-Correcting Parity-Check| STOPPING|2023 Aug 26 08:46:08|1693035968|1692999008|1693008026|0|-4|STARTED|0|5863140880|11718885324|0|check P|Scheduled Non-Correcting Parity-Check| PAUSE (RESTART)|2023 Aug 26 08:46:09|1693035969|1692999008|1693008026|0|-4|STARTED|0|5863140880|11718885324|0|check P|Scheduled Non-Correcting Parity-Check| RESUME (RESTART)|2023 Aug 26 08:57:18|1693036638|1693036628|0|0|0|STARTED|11718885324|5863827540|11718885324|0|check P|No array operation in progress| RESUME|2023 Aug 26 22:30:07|1693085407|1693036628|1693036640|0|-4|STARTED|0|5864121344|11718885324|0|check P|Scheduled Non-Correcting Parity-Check| PAUSE|2023 Aug 27 07:00:06|1693116006|1693085407|0|0|0|STARTED|11718885324|9213726048|11718885324|0|check P|Scheduled Non-Correcting Parity-Check| RESUME|2023 Aug 27 22:30:08|1693171808|1693085407|1693116007|0|-4|STARTED|0|9213817272|11718885324|0|check P|Scheduled Non-Correcting Parity-Check| PAUSE|2023 Aug 28 07:00:07|1693202407|1693171809|1693194257|0|0|STARTED|0|0|11718885324|0|check P|No array operation in progress| PAUSE|2023 Aug 29 07:00:08|1693288808|1693171809|1693194257|0|0|STARTED|0|0|11718885324|0|check P|No array operation in progress| PAUSE|2023 Aug 30 07:00:06|1693375206|1693171809|1693194257|0|0|STARTED|0|0|11718885324|0|check P|No array operation in progress| PAUSE|2023 Aug 31 07:00:07|1693461607|1693171809|1693194257|0|0|STARTED|0|0|11718885324|0|check P|No array operation in progress| PAUSE|2023 Sep 01 07:00:06|1693548006|1693171809|1693194257|0|0|STARTED|0|0|11718885324|0|check P|No array operation in progress| PAUSE|2023 Sep 02 07:00:07|1693634407|1693171809|1693194257|0|0|STARTED|0|0|11718885324|0|check P|No array operation in progress| PAUSE|2023 Sep 03 07:00:07|1693720807|1693171809|1693194257|0|0|STARTED|0|0|11718885324|0|check P|No array operation in progress| PAUSE|2023 Sep 04 07:00:07|1693807207|1693171809|1693194257|0|0|STARTED|0|0|11718885324|0|check P|No array operation in progress| PAUSE|2023 Sep 04 13:50:11|1693831811|1693171809|1693194257|0|0|STARTED|0|0|11718885324|0|check P|No array operation in progress| This is with the 2023.09.03 version of the plugin. I've attached diagnostics, and a syslog with logging set to Testing. Thanks! parity.txtcelestia-diagnostics-20230904-1400.zip
-
[Plugin] CA Appdata Backup / Restore v2.5
ElectricBadger replied to KluthR's topic in Plugin Support
Ah, there's the problem. I was still running unRAID 6.9.2. Although 6.12 is still only in the RC stage — but at least I'm now on 6.11.5. Not sure why unRAID stopped telling me there were updates available, but thanks for reminding me 😁 -
[Plugin] CA Appdata Backup / Restore v2.5
ElectricBadger replied to KluthR's topic in Plugin Support
Is there a way to specify the order in which containers should be backed up? It takes quite a while for the GitLab backup to run, and I'd like to specify that it run first so that it's finished when I need it in the morning. I also have a couple of questions about the settings page: Is it possible to have a "don't show this again" option on the warning popup saying that Docker containers will be stopped before the backup runs and restarted afterwards? I've seen it about twenty times now. I know. It's annoying to have to keep dismissing the alert every time — it reminds me of Windows Vista! The support link at the bottom of the page still goes to the old thread. That means clicking it, then clicking "go to post" on the pinned new thread announcement, then clicking the link to the new thread. It would be much easier if the link could go straight to the new thread, possibly with a note added saying "an older, read-only, thread is available here"… (Ooh, just noticed one more thing. I have /mnt/user/appdata on an SSD, but I also have /mnt/user/appdata_hd for things that take up too much space for an SSD and don't need the speed. Is there a way to get it to look at both of these? It seems like it can only do one or the other…) -
I am getting this problem as well — it sits a "checking issues" for an unacceptably long time, with no indication that it will ever complete. Would it be possible for the issue checker to output a percentage progress, just so users know whether they should hang around waiting for it or come back tomorrow?
-
I had to upgrade the base OS Pihole that provides DHCP, and now it will not resolve my unRAID server in DNS because the unRAID server has not asked for a new DHCP lease. Forcing unRAID to renew its DHCP lease proved to be more difficult than I'd hoped. It would be great for there to be a "renew DHCP lease" button next to each interface in Settings > Network Settings, but there is not. Online tutorials say to use `dhclient`, but it's not installed. Eventually I realised that you could do it with killall -HUP dhcpcd so I wanted to leave this here in case anybody else is having trouble (but also to ask for a Renew Lease button in the UI )
- 1 reply
-
- 1
-

-
Thanks — I had forgotten about Previous Apps. That would probably have saved a lot of time 🤦♂️ For some reason I didn't get the Reinstall from Previous option. I don't have a different version of the GitLab container in Previous Apps, so I'm guessing I did click on the same one that I was using previously, but it's probably too late to find out what happened there… I'm not even sure why that environment variable is added via Extra Parameters (I suspect I was following a set of install instructions that were incorrect) but I'll try adding it in the correct way when I have a bit more time. Not having to deal with the escaping is reason enough to make the switch 🙂
-
After reinstalling the container, it seemed to zero the databases and start afresh, even though it was pointed at the same appdata locations. It's a good job I had a backup, even though it took two tries to restore the user database and I still don't have the projects restored! Mismatching quotes in an environment variable absolutely should not cause this level of data loss.
-
If an error is made in the Extra Parameters setting when configuring a Docker container, the container is not added to the list of containers. If an error is made when editing this setting for an existing container, the container is removed from the list of installed containers and the user configuration is lost. There is no warning or confirmation before this happens. To reproduce: Install the GitLab CE container and start it. Edit the container settings. Add the following to Extra Parameters: --env GITLAB_OMNIBUS_CONFIG="external_url 'https://git.example.com';nginx['custom_gitlab_server_config'] = "location /-/plantuml/ { \n proxy_cache off; \n proxy_pass http://plantuml:8080/; \n}\n";prometheus_monitoring['enable']=false;" Note that the code pasted from https://docs.gitlab.com/ee/administration/integration/plantuml.html uses double quotes which should have been escaped, as it's already inside double quotes. An easy error to miss, but one with a hefty penalty, as it causes the container creation to fail. This causes the container to vanish; when reinstalled, any existing configuration changes are lost and the container has its default settings once more. Expected behaviour: the container remains installed, in a stopped state, with its existing config. The user is free to edit that config until they come up with one that works. I'm marking this as Urgent as it is, technically, a data loss bug (while I didn't lose any data from the container's volumes, I did have to recreate all the config options. If I didn't have a copy of that Extra Parameters, which I've pasted a sanitised version of below, it would have taken hours to get the container up and running again.) --env GITLAB_OMNIBUS_CONFIG="external_url 'https://git.example.com';registry_external_url 'https://registry.example.com';gitlab_rails['usage_ping_enabled']=false;gitlab_rails['lfs_enabled']=true;gitlab_rails['gitlab_ssh_host']='git.example.com';gitlab_rails['gitlab_email_from']='[email protected]';gitlab_rails['smtp_enable']=true;gitlab_rails['smtp_address']='mail.example.com';gitlab_rails['smtp_port']=25;gitlab_rails['smtp_authentication']=false;gitlab_rails['smtp_tls']=false;gitlab_rails['smtp_openssl_verify_mode']='none';gitlab_rails['smtp_enable_starttls_auto']=false;gitlab_rails['smtp_ssl']=false;gitlab_rails['smtp_force_ssl']=false;gitlab_rails['manage_backup_path']=false;gitlab_rails['backup_path']='/backups';gitlab_rails['backup_archive_permissions']=0644;gitlab_rails['backup_pg_schema']='public';gitlab_rails['backup_keep_time']=604800;nginx['listen_port']=9080;nginx['listen_https']=false;nginx['hsts_max_age']=0;nginx['client_max_body_size']='0';nginx['custom_gitlab_server_config']='location /-/plantuml/ {\nproxy_cache off;proxy_pass http://plantuml:14480/;\n}\n';registry_nginx['listen_port']=9381;registry_nginx['listen_https']=false;registry_nginx['client_max_body_size']='0';registry_nginx['enable']=true;registry['enable']=true;gitlab_rails['pipeline_schedule_worker_cron'] = '7,37 * * * *';prometheus_monitoring['enable']=false;postgresql['auto_restart_on_version_change']=false" celestia-diagnostics-20220801-0905.zip
-
If I stop the array and then restart it, all Docker containers that have autostart set to ON are restarted. The same does not apply to VMs: they only autostart after a full reboot, and must be restarted manually in this case. This is really annoying, as I usually forget to do this and don't notice until I try to use something that's running on a VM and find it's not working. Would it be possible for autostart to be consistent between Docker and VMs, and for both to autostart things after an array stop/start? celestia-diagnostics-20220219-1402.zip
-
Yes, the plugin autoupdates, so it's current. Looks like Firefox doesn't support the `list` attribute for `input type='color'`, so not a lot you can do here. I'll use Vivaldi for when I need to edit colours. Thanks!
-
Everything I'm reading suggests that I should get a dropdown when I click on a custom colour control, which includes an option to reset the colour to its default. However, in Firefox on macOS, I just get the standard system colour picker. The posts I read were from a while ago — has the behaviour changed since then? There no longer seems to be a way to reset a colour to default without resetting them all to default…


