

MowMdown
-
Posts
194 -
Joined
-
Last visited
Recent Profile Visitors
2281 profile views





MowMdown's Achievements
")
-
Having issues with Sonarr seeing available space
MowMdown replied to CyberKNight's topic in General Support
My guess is that no data under /…/…/media/TV Shows was written to the array so it sonarr didn’t yet see the full array size. It was only looking at the SSD by itself. once a folder was created on the array, it probably picked up on the fact the storage size was now SSD+Array -
Yes sonarr and radarr have an import function. It will rename and move the files when they’ve finished downloading. You shouldn’t have to do anything manually. the *arrs apps also have batch renaming for already imported files.
-
You would use the “unbalance” plugin but typically there’s no need to balance drives.
-
You tell the *arrs what to rename them on import. *arrs > settings > media management
-
UNRAID Parity SMART Error IronWolf Hard Drive
MowMdown replied to rsutter's topic in General Support
Unraid biggest selling feature is being able to mix disks from all types of sizes and manufacturers. -
Click the little icon to the left of “Disk1” it will let you browse the contents on that disk. alternativly, if you ssh into your machine or click on the webgui terminal, you can navigate through /mnt/user or /mnt/disk1 (never copy data from/to /mnt/user to another disk)
-
Use the array as unraid intends but you can have as many “cache pools” as you want. Cache pools can be just about any configuration you want them to be in. Just Disks, RAID0, RAID1, RAIDZ, ZFS MIRROR, etc each cache pool can be its own setup too. Pool1 can be 4 SSDs that aren’t in any kind of RAID. Pool2 can be a RAID1 pool.
-
Do you have "Cache Dirs" plugin installed?
-
I think I found the culprit maybe? nobody 19635 0.8 2.3 1609296 388820 ? Ssl 10:06 5:39 python3 -m homeassistant -c /config Before and After stopping HA docker and restarting unraid mDNS: After, clearly homeassinstant is what I think is the source for the mDNS conflicting issue
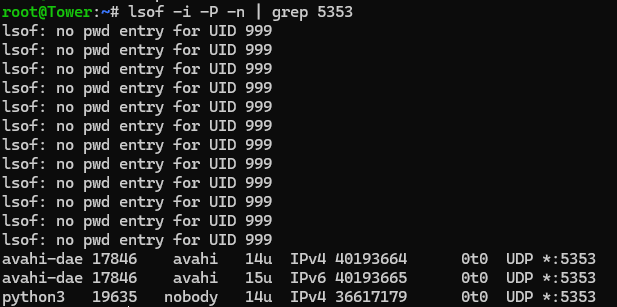
-
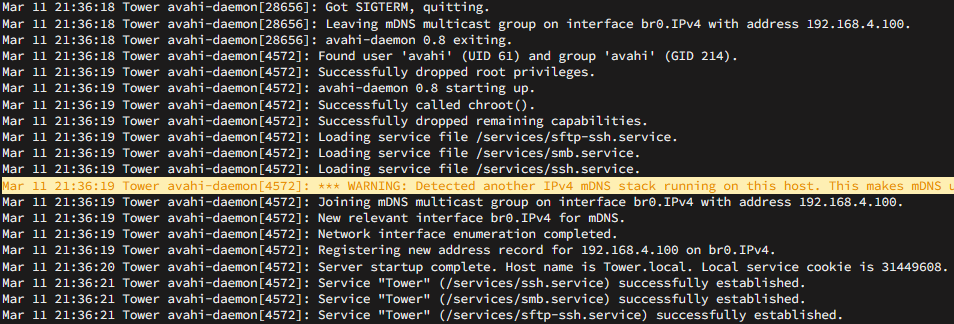
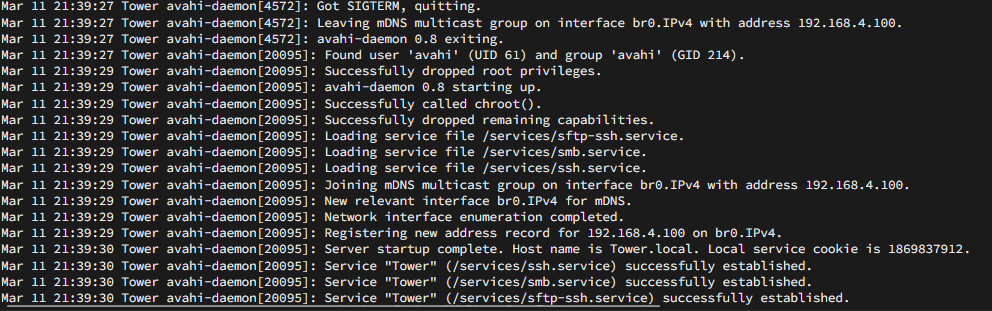
@JorgeB I went ahead and disabled IPv6 and that seemed to have worked however, It's not the most ideal solution as it doesn't fix the underlying cause. Here's some more log from yesterday before I shut IPv6 off. I'm thinking whatever is causing the WARNING is the cause for the log spam. The only docker I can think of that would maybe cause this is pi-hole? Do you see anything else in my diags pointing to a culprit? Mar 9 22:11:34 Tower emhttpd: Starting services... Mar 9 22:11:34 Tower emhttpd: shcmd (265570): chmod 0777 '/mnt/user/docker' Mar 9 22:11:34 Tower emhttpd: shcmd (265571): chown 'nobody':'users' '/mnt/user/docker' Mar 9 22:11:34 Tower emhttpd: shcmd (265574): /etc/rc.d/rc.avahidaemon restart Mar 9 22:11:34 Tower root: Stopping Avahi mDNS/DNS-SD Daemon: stopped Mar 9 22:11:34 Tower avahi-daemon[17101]: Got SIGTERM, quitting. Mar 9 22:11:34 Tower avahi-daemon[17101]: Leaving mDNS multicast group on interface br0.IPv6 with address fdf0:6a76:b27e:1:ec4:7aff:fe64:9e01. Mar 9 22:11:34 Tower avahi-daemon[17101]: Leaving mDNS multicast group on interface br0.IPv4 with address 192.168.4.100. Mar 9 22:11:34 Tower avahi-dnsconfd[17111]: read(): EOF Mar 9 22:11:34 Tower avahi-daemon[17101]: avahi-daemon 0.8 exiting. Mar 9 22:11:35 Tower root: Starting Avahi mDNS/DNS-SD Daemon: /usr/sbin/avahi-daemon -D Mar 9 22:11:35 Tower avahi-daemon[26563]: Found user 'avahi' (UID 61) and group 'avahi' (GID 214). Mar 9 22:11:35 Tower avahi-daemon[26563]: Successfully dropped root privileges. Mar 9 22:11:35 Tower avahi-daemon[26563]: avahi-daemon 0.8 starting up. Mar 9 22:11:35 Tower avahi-daemon[26563]: Successfully called chroot(). Mar 9 22:11:35 Tower avahi-daemon[26563]: Successfully dropped remaining capabilities. Mar 9 22:11:35 Tower avahi-daemon[26563]: Loading service file /services/sftp-ssh.service. Mar 9 22:11:35 Tower avahi-daemon[26563]: Loading service file /services/ssh.service. Mar 9 22:11:35 Tower avahi-daemon[26563]: *** WARNING: Detected another IPv4 mDNS stack running on this host. This makes mDNS unreliable and is thus not recommended. *** Mar 9 22:11:35 Tower avahi-daemon[26563]: *** WARNING: Detected another IPv6 mDNS stack running on this host. This makes mDNS unreliable and is thus not recommended. *** Mar 9 22:11:35 Tower avahi-daemon[26563]: Joining mDNS multicast group on interface br0.IPv6 with address fdf0:6a76:b27e:1:ec4:7aff:fe64:9e01. Mar 9 22:11:35 Tower avahi-daemon[26563]: New relevant interface br0.IPv6 for mDNS. Mar 9 22:11:35 Tower avahi-daemon[26563]: Joining mDNS multicast group on interface br0.IPv4 with address 192.168.4.100. Mar 9 22:11:35 Tower avahi-daemon[26563]: New relevant interface br0.IPv4 for mDNS. Mar 9 22:11:35 Tower avahi-daemon[26563]: Network interface enumeration completed. Mar 9 22:11:35 Tower avahi-daemon[26563]: Registering new address record for fdf0:6a76:b27e:1:ec4:7aff:fe64:9e01 on br0.*. Mar 9 22:11:35 Tower avahi-daemon[26563]: Registering new address record for 2604:2d80:968e:b300:ec4:7aff:fe64:9e01 on br0.*. Mar 9 22:11:35 Tower avahi-daemon[26563]: Registering new address record for 192.168.4.100 on br0.IPv4. Mar 9 22:11:35 Tower emhttpd: shcmd (265575): /etc/rc.d/rc.avahidnsconfd restart Mar 9 22:11:35 Tower root: Stopping Avahi mDNS/DNS-SD DNS Server Configuration Daemon: stopped Mar 9 22:11:35 Tower root: Starting Avahi mDNS/DNS-SD DNS Server Configuration Daemon: /usr/sbin/avahi-dnsconfd -D Mar 9 22:11:35 Tower avahi-dnsconfd[26572]: Successfully connected to Avahi daemon. Mar 9 22:11:35 Tower avahi-daemon[26563]: Server startup complete. Host name is Tower.local. Local service cookie is 2084411687. Mar 9 22:11:36 Tower avahi-daemon[26563]: Registering new address record for fd91:1ac0:7f43:c44:ec4:7aff:fe64:9e01 on br0.*. Mar 9 22:11:36 Tower avahi-daemon[26563]: Service "Tower" (/services/ssh.service) successfully established. Mar 9 22:11:36 Tower avahi-daemon[26563]: Service "Tower" (/services/sftp-ssh.service) successfully established.
-
I’ve searched the forums, Reddit, Google, etc. I’m struggling what’s causing avahi daemon to spam my logs with “withdrawing/registering” over and over. there are no host-name conflicts that I am aware of on my network. nothing else is using .local TLD either. there are no static IPv6 addresses assigned to any of my devices. It’s even set to automatic/dhcp in my network settings on unraid. attached are the diagnostics. tower-diagnostics-20240309-1118.zip
-
Well that's to be expected. You've set your share to be moved off of your pool onto the array. No idea why you'd want to snapshot an empty dataset that's never going to have data in it? Edit: @Iker I have a QOL suggest for the snapshot admin pop-up window. Instead of the pop-up window, can the snapshots just expand below the selected dataset? I have issues with the pop-up window on small screens where the width is very narrow requiring horizontal scrolling even when using landscape orientation.
-
@MilkSomelier Stop docker service entirely, enable destructive mode in ZFS Master settings, click the action button > Convert to Dataset, then you also need to convert each individual appdata folder too or else you won't be able to restore individual docker appdata.
-
Guide: How To Use Rclone To Mount Cloud Drives And Play Files
MowMdown replied to DZMM's topic in Plugins and Apps
It's in memory mounted as a tempfs iirc -
Guide: How To Use Rclone To Mount Cloud Drives And Play Files
MowMdown replied to DZMM's topic in Plugins and Apps
just change --vfs-cache-mode full to --vfs-cache-mode off




