

David Spivey
-
Posts
27 -
Joined
-
Last visited
David Spivey's Achievements
")
Noob (1/14)
5
Reputation
-
 dstorage-diagnostics-20220330-0713.zip
dstorage-diagnostics-20220330-0713.zip -
I recently upgraded one of my 2TB drives to an 8TB. The process was successful, and before this, I was having no issues. A day or two afterwards, unraid is telling me one of my drives has write errors. I don't know what to blame for this write error. Can anyone provide recommendations? Here is the relevant error in the logs. Mar 24 03:00:02 DStorage kernel: sd 34:0:1:0: [sdk] tag#422 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=0x08 cmd_age=0s Mar 24 03:00:02 DStorage kernel: sd 34:0:1:0: [sdk] tag#422 Sense Key : 0x3 [current] Mar 24 03:00:02 DStorage kernel: sd 34:0:1:0: [sdk] tag#422 ASC=0x11 ASCQ=0x0 Mar 24 03:00:02 DStorage kernel: sd 34:0:1:0: [sdk] tag#422 CDB: opcode=0x88 88 00 00 00 00 00 00 23 c7 b0 00 00 00 08 00 00 Mar 24 03:00:02 DStorage kernel: blk_update_request: critical medium error, dev sdk, sector 2344880 op 0x0:(READ) flags 0x0 phys_seg 1 prio class 0 Mar 24 03:00:02 DStorage kernel: md: disk9 read error, sector=2344816 Mar 24 03:00:04 DStorage kernel: mpt2sas_cm1: log_info(0x31110610): originator(PL), code(0x11), sub_code(0x0610) Mar 24 03:00:04 DStorage kernel: sd 34:0:1:0: [sdk] tag#430 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=0x08 cmd_age=1s Mar 24 03:00:04 DStorage kernel: sd 34:0:1:0: [sdk] tag#430 Sense Key : 0x4 [current] Mar 24 03:00:04 DStorage kernel: sd 34:0:1:0: [sdk] tag#430 ASC=0x44 ASCQ=0x0 Mar 24 03:00:04 DStorage kernel: sd 34:0:1:0: [sdk] tag#430 CDB: opcode=0x88 88 00 00 00 00 01 64 ed 79 a8 00 00 00 20 00 00 Mar 24 03:00:04 DStorage kernel: blk_update_request: critical target error, dev sdk, sector 5988252072 op 0x0:(READ) flags 0x0 phys_seg 4 prio class 0 Mar 24 03:00:04 DStorage kernel: md: disk9 read error, sector=5988252008 Mar 24 03:00:04 DStorage kernel: md: disk9 read error, sector=5988252016 Mar 24 03:00:04 DStorage kernel: md: disk9 read error, sector=5988252024 Mar 24 03:00:04 DStorage kernel: md: disk9 read error, sector=5988252032 Mar 24 03:00:04 DStorage kernel: sd 34:0:1:0: [sdk] tag#436 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=0x08 cmd_age=0s Mar 24 03:00:04 DStorage kernel: sd 34:0:1:0: [sdk] tag#436 Sense Key : 0x4 [current] Mar 24 03:00:04 DStorage kernel: sd 34:0:1:0: [sdk] tag#436 ASC=0x44 ASCQ=0x0 Mar 24 03:00:04 DStorage kernel: sd 34:0:1:0: [sdk] tag#436 CDB: opcode=0x8a 8a 00 00 00 00 01 64 ed 79 a8 00 00 00 20 00 00 Mar 24 03:00:04 DStorage kernel: blk_update_request: critical target error, dev sdk, sector 5988252072 op 0x1:(WRITE) flags 0x0 phys_seg 4 prio class 0 Mar 24 03:00:04 DStorage kernel: md: disk9 write error, sector=5988252008 Mar 24 03:00:04 DStorage kernel: md: disk9 write error, sector=5988252016 Mar 24 03:00:04 DStorage kernel: md: disk9 write error, sector=5988252024 Mar 24 03:00:04 DStorage kernel: md: disk9 write error, sector=5988252032
-
Ok thanks for your help Jorge. Without your instruction, I would have most likely lost data.
-
Array comes online, disk is mounted, no lost+found folder when examining Index of /mnt/disk7 Is there anything else I should do now except replace the disk / cables? A parity check had started a while back, when the power problems were occurring, and was aborted. Do I need to do one now, or wait until the disk is replaced?
-
Phase 1 - find and verify superblock... - block cache size set to 319640 entries Phase 2 - using internal log - zero log... zero_log: head block 674161 tail block 674157 ALERT: The filesystem has valuable metadata changes in a log which is being destroyed because the -L option was used. - scan filesystem freespace and inode maps... - found root inode chunk Phase 3 - for each AG... - scan and clear agi unlinked lists... - process known inodes and perform inode discovery... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - agno = 4 - agno = 5 - agno = 6 - agno = 7 - agno = 8 - agno = 9 - agno = 10 - agno = 11 - agno = 12 - agno = 13 - agno = 14 - agno = 15 - process newly discovered inodes... Phase 4 - check for duplicate blocks... - setting up duplicate extent list... - check for inodes claiming duplicate blocks... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - agno = 4 - agno = 5 - agno = 6 - agno = 7 - agno = 8 - agno = 9 - agno = 10 - agno = 11 - agno = 12 - agno = 13 - agno = 14 - agno = 15 Phase 5 - rebuild AG headers and trees... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - agno = 4 - agno = 5 - agno = 6 - agno = 7 - agno = 8 - agno = 9 - agno = 10 - agno = 11 - agno = 12 - agno = 13 - agno = 14 - agno = 15 - reset superblock... Phase 6 - check inode connectivity... - resetting contents of realtime bitmap and summary inodes - traversing filesystem ... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - agno = 4 - agno = 5 - agno = 6 - agno = 7 - agno = 8 - agno = 9 - agno = 10 - agno = 11 - agno = 12 - agno = 13 - agno = 14 - agno = 15 - traversal finished ... - moving disconnected inodes to lost+found ... Phase 7 - verify and correct link counts... Maximum metadata LSN (2:674385) is ahead of log (1:2). Format log to cycle 5. XFS_REPAIR Summary Tue Nov 23 11:09:15 2021 Phase Start End Duration Phase 1: 11/23 11:07:16 11/23 11:07:16 Phase 2: 11/23 11:07:16 11/23 11:07:27 11 seconds Phase 3: 11/23 11:07:27 11/23 11:08:11 44 seconds Phase 4: 11/23 11:08:11 11/23 11:08:11 Phase 5: 11/23 11:08:11 11/23 11:08:14 3 seconds Phase 6: 11/23 11:08:14 11/23 11:08:52 38 seconds Phase 7: 11/23 11:08:52 11/23 11:08:52 Total run time: 1 minute, 36 seconds done
-
Phase 1 - find and verify superblock... - block cache size set to 319640 entries Phase 2 - using internal log - zero log... zero_log: head block 674161 tail block 674157 ERROR: The filesystem has valuable metadata changes in a log which needs to be replayed. Mount the filesystem to replay the log, and unmount it before re-running xfs_repair. If you are unable to mount the filesystem, then use the -L option to destroy the log and attempt a repair. Note that destroying the log may cause corruption -- please attempt a mount of the filesystem before doing this.
-
I don't know what I'm doing wrong, but I started the array in maintenance mode, changed the options to -nv as recommended, clicked check, and after hours refreshing the page it still looks like nothing is happening. How do I check to see if the check button actually started anything?
-
I'm not sure how to proceed, but I'm sure I should not format anything. I have attached a log and screenshot. The WDC_WD80EDAZ-11TA3A0_VGH5VVGG was Disk7. dstorage-diagnostics-20211122-1114.zip
.thumb.png.eb19e56ec26375f6fc2b6732216f89f3.png)
-
One of the HBA cards went down and unraid sent me an email saying many of my drives were offline. I started shutting down unraid, but it hung and would not shut down cleanly. The diags for that are attached, as well as the diags after rebooting with the new card installed. Now unraid says two of my drives are disabled. How should I proceed? Should I make unraid rebuild both drives? dstorage-diagnostics-20210824-1128.zip dstorage-diagnostics-20210824-1328.zip
-
dstorage-diagnostics-20210819-2345.zip
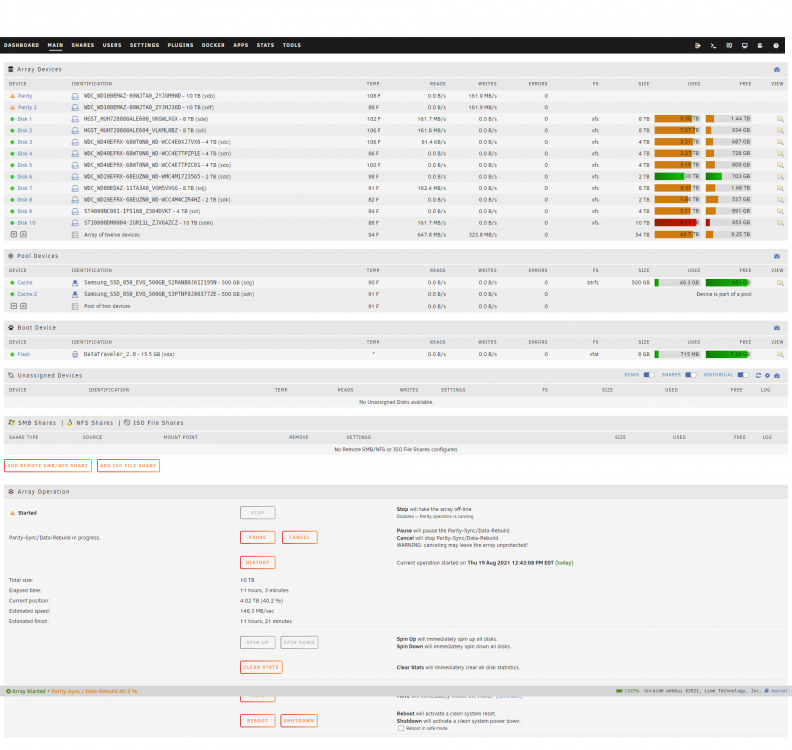
-
Yep. New config already done. All drives carefully assigned to their proper places, and it's rebuilding parity now.
-
Thanks for the concern. That was a reasonable concern considering how I messed things up already. Fortunately I had already been careful enough to go into disk settings and disable auto start before I rebooted to put the drives in.
-
@JorgeB I took the original drives and tested them in another system. After diags, they're fine. If I understand correctly, I should put the original drives back in and remove the formatted ones, then create a new config. If I create a new config, and make sure the parity drives are parity drives and the data drives are data drives, does it matter the order of the slots the drives are in?
-
As far as assigning the disks and rebuilding parity, wouldn't that be assuming that the drives unraid previously said were bad were actually good? If the drives are actually going bad won't parity sync fail? It looks like I need to do some tests on these drives to see if they're bad first.
-
This is the disk from disk1's slot. It is mountable and readable. The other drive that was unassigned from disk7's slot is outside of the system.


.png.1521aaa32fe389caa7a98408adffada9.png)
