

swells
-
Posts
150 -
Joined
-
Last visited
swells's Achievements
")
Apprentice (3/14)
1
Reputation
-
Ok, I think I know how to proceed but I wanted the opinion of others before I do anything. I do the auto parity check once a month on the first (without corrections). Since my last check February 1st I had a stick of memory go bad. I caught it quickly because of other issues I was having and replaced it. Fast forward to March 1st and I have 12 errors. I assume these are thanks to my bad memory. My thoughts are to run another check (again without corrections) verify the errors are the same as the first pass and if they are, let the check correct the errors. Am I off here? Thanks!!
-
Yeah, I was just coming here to say I think I have tracked the issue to the "Auto-cancel stalled workers" option being on. I turned it off last night and have not had an issue since. I have had a few fail, most are .ts or .m2ts. Thanks for the help!
-
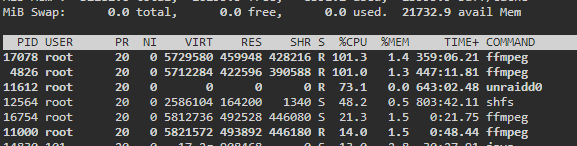
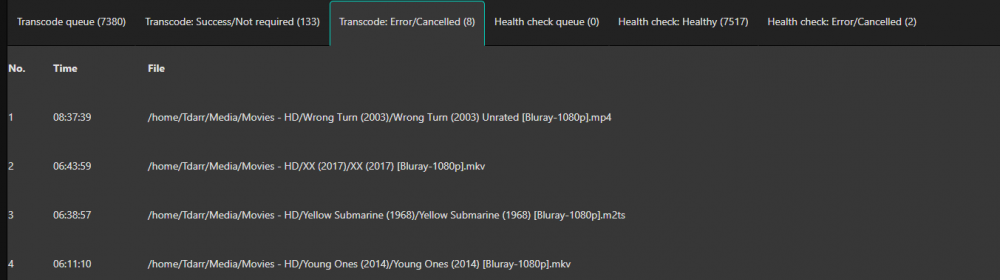
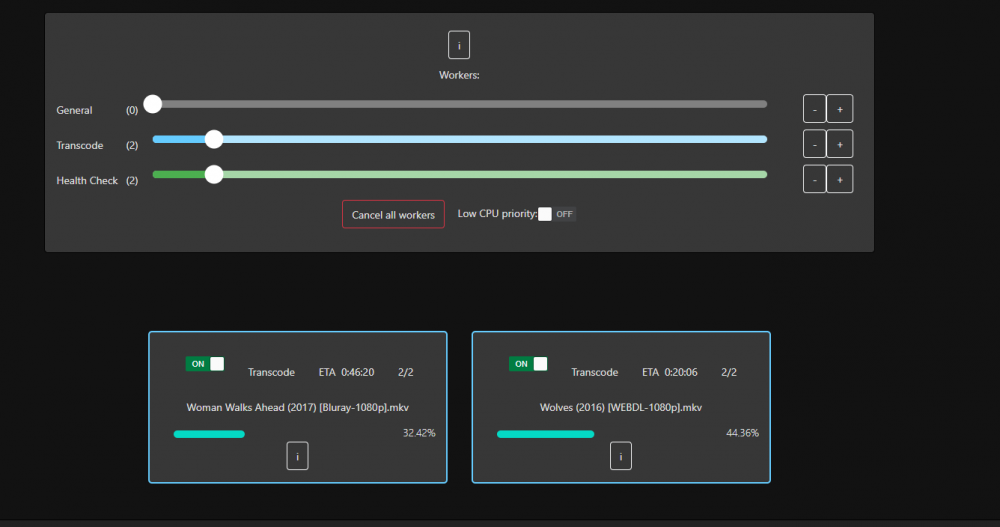
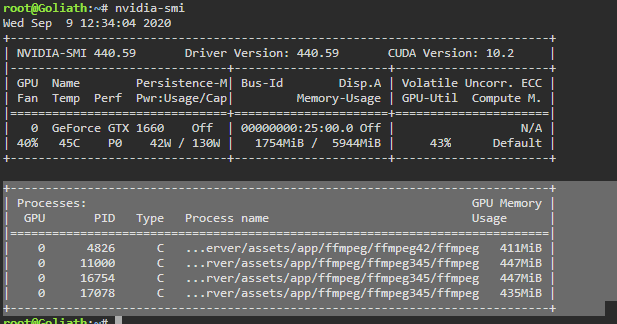
Ok it started happening again this today and I was able to catch it early. I have two threads enabled for transcode and two health check. There are currently 4 processes running, two of them are movies that are now in the Transcode: Error/Cancelled column. Both of them say "Item was cancelled by user." I'm attaching some screenshots from the time I noticed this. Here are the processes: 17078 100 1.3 5729580 459948 ? Rl 06:38 355:59 /home/Tdarr/Tdarr/bundle/programs/server/assets/app/ffmpeg/ffmpeg345/ffmpeg -c:v h264_cuvid -i /home/Tdarr/Media/Movies - HD/XX (2017)/XX (2017) [Bluray-1080p].mkv -map 0 -map -0:d -c:v hevc_nvenc -rc:v vbr_hq -qmin 0 -cq:v 31 -b:v 2500k -maxrate:v 5000k -preset medium -rc-lookahead 32 -spatial_aq:v 1 -aq-strength:v 8 -c:a copy -c:s copy -max_muxing_queue_size 4096 /home/Tdarr/cache/XX (2017) [Bluray-1080p]-TdarrCacheFile-u9gUbCn-z.mkv 4826 100 1.2 5712284 422596 ? Rl 05:11 444:04 /home/Tdarr/Tdarr/bundle/programs/server/assets/app/ffmpeg/ffmpeg42/ffmpeg -c:v h264_cuvid -i /home/Tdarr/Media/Movies - HD/Young Ones (2014)/Young Ones (2014) [Bluray-1080p].mkv -map 0 -map -0:d -c:v hevc_nvenc -rc:v vbr_hq -qmin 0 -cq:v 31 -b:v 2500k -maxrate:v 5000k -preset medium -rc-lookahead 32 -spatial_aq:v 1 -aq-strength:v 8 -c:a copy -c:s copy -max_muxing_queue_size 4096 /home/Tdarr/cache/Young Ones (2014) [Bluray-1080p]-TdarrCacheFile-_olUQbBMe.mkv 16754 21.9 1.4 5812736 492792 ? Sl 12:33 1:13 /home/Tdarr/Tdarr/bundle/programs/server/assets/app/ffmpeg/ffmpeg345/ffmpeg -c:v h264_cuvid -i /home/Tdarr/Media/Movies - HD/Wolves (2016)/Wolves (2016) [WEBDL-1080p].mkv -map 0 -map -0:d -c:v hevc_nvenc -rc:v vbr_hq -qmin 0 -cq:v 31 -b:v 2500k -maxrate:v 5000k -preset medium -rc-lookahead 32 -spatial_aq:v 1 -aq-strength:v 8 -c:a copy -map -0:a:0 -c:s copy -map -0:s:0 -max_muxing_queue_size 4096 /home/Tdarr/cache/Wolves (2016) [WEBDL-1080p]-TdarrCacheFile-6mulRpdAg.mkv 11000 13.7 1.5 5821572 494684 ? Sl 12:29 1:18 /home/Tdarr/Tdarr/bundle/programs/server/assets/app/ffmpeg/ffmpeg345/ffmpeg -c:v h264_cuvid -i /home/Tdarr/Media/Movies - HD/Woman Walks Ahead (2017)/Woman Walks Ahead (2017) [Bluray-1080p].mkv -map 0 -map -0:d -c:v hevc_nvenc -rc:v vbr_hq -qmin 0 -cq:v 31 -b:v 2500k -maxrate:v 5000k -preset medium -rc-lookahead 32 -spatial_aq:v 1 -aq-strength:v 8 -c:a copy -c:s copy -max_muxing_queue_size 4096 /home/Tdarr/cache/Woman Walks Ahead (2017) [Bluray-1080p]-TdarrCacheFile-dN0kys-vG.mkv
-
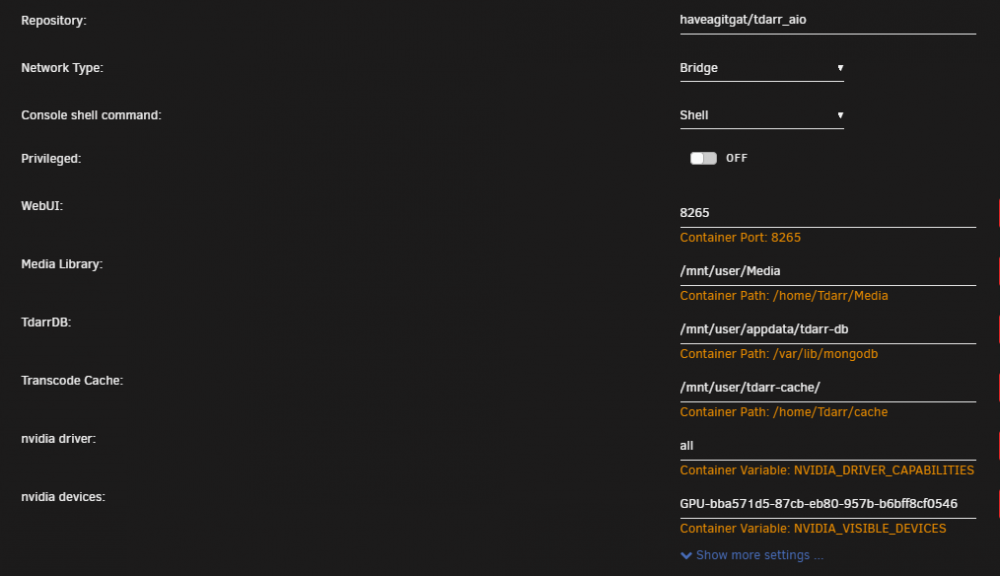
I'm using tdarr_aio. I am running two plugins, Migz-Order Streams and DOOM Tiered H265 MKV. Attached a screen grab of the docker config. I will wait and see if/when this happens again and send the info tab while its happening if possible. Otherwise, when I recover all they ever say is " Item was cancelled by user". I have both Auto-cancel stalled workers and Linux FFmpeg NVENC binary (3.4.5 for unRAID compatibility) set to ON. Last night I completely uninstalled/removed the tdarr docker and reinstalled everything starting fresh. So far it is running without issue, we'll see if it lasts.
-
Hey all. I posted about this on the subreddit for tdarr but figured I would post here as well. At this point I’m not running tdarr because of the problem I am having. Every few days or so I run into an issue where tdarr spawns a ton (20-30) ffmpeg processes and my server comes to a crawl. When this happens I have to shutdown my server hard as I can’t seem to get it back when it’s pegged at 100%. When I get tdarr back running there’s a bunch of new “cancelled by user” items in the cancelled column. Like those were the ones transcoding and they never finish. I have tdarr set to do two transcode threads and two health check. Here is a screen cap to the process list when one of these situations occurred. https://imgur.com/a/qeQ80Rq
-
I used to have a much much smaller SSD as my cache drive (200GB), I ran the mover often to keep some room on the cache for downloads, etc. I just never changed this behavior because it has never been a problem. My scheduled parity check does not do parity corrections. It's possible the auto parity check after an unclean shutdown does? I'm not 100% certain on the behavior of that. Thanks for this! Indeed it looks like it does not. I might just drop back down to single parity until I upgrade hardware in the future.
-
Sorry I meant to attach it and completely forgot. goliath-diagnostics-20190502-1058.zip
-
Hello all, I recently moved to dual parity with 2x 10TB drives. My first monthly parity check began yesterday morning. I noticed when I returned from work that I could not access any of my dockers or the webgui. I tried to access the server via SSH but that failed as well. Pings were also timing out. I did notice that all of the activity LED's were active on the HDD's as if the parity check was still underway. I forced the server down and rebooted, which kicked off another parity check of course. I let this go a while and all seemed well. Until this morning. The parity check was at around 35% and the dockers were really slow to respond and would often time out. The webgui was having the same problem and file transfers to or from the array would not complete. I tried to grab a 2GB file copied to my desktop and it started at full speed and slowed to 0bps. Before cancelling the parity check I stopped all of my dockers, this did not help. I stopped the parity check and that cleared everything up. What should I be looking at here? Any suggestions would be appreciated. Thanks!
-
Thanks for your help!
-
Well that explains that. I can move the drive(s) that are connected to it to free slots on the H310. Is there a 2 port SATA3 card that is recommended to replace it?
-
Looks like it is. This is the card. One of the reviews states the card has a Marvell 88SE9128. https://www.amazon.com/gp/product/B003GS8VA4/ref=oh_aui_search_detailpage?ie=UTF8&psc=1 And this is from my diagnostics. Marvell no bueno? 04:00.0 SATA controller [0106]: Marvell Technology Group Ltd. 88SE9128 PCIe SATA 6 Gb/s RAID controller [1b4b:9128] (rev 20) Subsystem: Marvell Technology Group Ltd. 88SE9128 PCIe SATA 6 Gb/s RAID controller [1b4b:9128] Kernel driver in use: ahci Kernel modules: ahci
-
Hi All, Looking for some help with an issue. I searched around here a bit and couldn't find anything specific to what I am seeing, but if there is something out there, please forgive me and point me in the right direction please. I am having an issue that has occurred since the beginning of the year. I have been having an issue with parity sync and have been getting 5 sync errors every other month or so, then I correct them usually after I confirm they are there, and then wont see them for a month or so and then they come back. And they are always in the same sectors. I started tracking the sector a few months ago and copied them off into a separate text file to keep. Below are the details. Current state of my server is, I just within the past two weeks transferred all hardware from a Antec 900 with three 5in3 cages to a norco 4224. So all cables, back planes, caddies, etc are all different since the last time I saw the sync errors. If it was memory I would think it would be at different sectors right? Could it be bad sectors on a single drive? What do I need to do? Long SMART test on each drive? All the SATA cards stayed the same, I have a Dell PERC H310 and a single 2 port card coupled with my 6x on board ports currently in use. When I moved to the norco chassis I added an additional H310 but it is currently not in use. As you can see here, I will get the sync errors, run again with correct again, they get corrected and then i get a month or more of no errors and then they return. 2018-09-21, 14:34:05 19 hr, 35 min, 41 sec 113.4 MB/s OK 0 2018-09-18, 08:56:43 20 hr, 49 min, 55 sec 106.7 MB/s OK 5 2018-08-02, 01:59:33 23 hr, 59 min, 32 sec 92.6 MB/s OK 0 2018-07-01, 22:05:41 20 hr, 5 min, 40 sec 110.6 MB/s OK 5 2018-06-01, 20:42:18 18 hr, 42 min, 17 sec 118.8 MB/s OK 0 2018-05-21, 15:50:31 18 hr, 29 min, 50 sec 120.2 MB/s OK 5 2018-05-19, 04:26:08 18 hr, 37 min, 32 sec 119.3 MB/s OK 5 2018-05-18, 01:45:21 18 hr, 44 min, 55 sec 118.6 MB/s OK 0 2018-05-01, 19:08:03 21 hr, 34 min, 27 sec 103.0 MB/s OK 0 2018-04-29, 15:57:07 21 hr, 7 min, 35 sec 105.2 MB/s OK 0 2018-04-28, 16:28:48 20 hr, 49 min, 35 sec 106.7 MB/s OK 0 2018-04-27, 18:42:46 20 hr, 42 min, 24 sec 107.3 MB/s OK 5 2018-04-01, 22:57:58 20 hr, 57 min, 57 sec 106.0 MB/s OK 0 2018-03-03, 03:38:01 20 hr, 55 min, 32 sec 106.2 MB/s OK 5 2018-03-01, 23:02:53 21 hr, 2 min, 52 sec 105.6 MB/s OK 5 2018-02-03, 02:48:41 20 hr, 43 min, 30 sec 107.2 MB/s OK 5 2018-02-01, 22:46:09 20 hr, 46 min, 8 sec 107.0 MB/s OK 5 2018-01-01, 23:16:40 21 hr, 16 min, 39 sec 104.5 MB/s OK 5 In July I started tracking the sector of the errors. Jul 1 05:30:30 Tower kernel: md: recovery thread: P incorrect, sector=2743151176 Jul 1 05:30:30 Tower kernel: md: recovery thread: P incorrect, sector=2743151184 Jul 1 05:30:30 Tower kernel: md: recovery thread: P incorrect, sector=2743151192 Jul 1 05:30:30 Tower kernel: md: recovery thread: P incorrect, sector=2743151200 Jul 1 05:30:30 Tower kernel: md: recovery thread: P incorrect, sector=2743151208 Jul 2 08:55:30 Tower kernel: md: recovery thread: P incorrect, sector=2743151176 Jul 2 08:55:30 Tower kernel: md: recovery thread: P incorrect, sector=2743151184 Jul 2 08:55:30 Tower kernel: md: recovery thread: P incorrect, sector=2743151192 Jul 2 08:55:30 Tower kernel: md: recovery thread: P incorrect, sector=2743151200 Jul 2 08:55:30 Tower kernel: md: recovery thread: P incorrect, sector=2743151208 Oct 1 04:46:49 Tower kernel: md: recovery thread: P incorrect, sector=2743151176 Oct 1 04:46:49 Tower kernel: md: recovery thread: P incorrect, sector=2743151184 Oct 1 04:46:49 Tower kernel: md: recovery thread: P incorrect, sector=2743151192 Oct 1 04:46:49 Tower kernel: md: recovery thread: P incorrect, sector=2743151200 Oct 1 04:46:49 Tower kernel: md: recovery thread: P incorrect, sector=2743151208 Any ideas? Any help here would be appreciated.
-
(USA) WD Easystore 8TB External $180 @ Best Buy + FS
swells replied to Hoopster's topic in Good Deals!
FWIW... I have purchased 7 of these EasyStore drives now over the last 8 months. The price has been between $180 and $130 when on sale depending on the model (NESN or NEBB). I have 5 RED drives and 2 "white" label drives. Everything on these drives is exactly the same. I even have 3 different model numbers. WD80EFZX, WD80EFAX, and WD80EMAZ. The only 2 differences I have noticed are the WD80EFZX drive actually shows the helium level stat while the other two models say unknown attribute. Even though it is attribute #22 on all the drives and shows the same number, etc. The other being the same drive also only has 128MB cache and the others have 256MB. All the drive info like firmware, etc is the same. There is no doubt on my mind that the white label drives are relabeled RED drives. These drives are totally worth picking up. You can preclear before shucking if you are worried about them. I have done that with two of them just because of ease. -
I did this exact migration myself and it was smooth. Backup the folder you have your Plex app in stalled in. I simply copied everything in what was for me //appdata/plex over to the array just in case. The copy will take a while since there are hundreds of thousands of small files that make up the meta data, but it's worth it for that piece of mind IMO. After that is complete, I took a screen shot of the settings page of the Phaze plugin and disabled it. Then went to the docker settings for Plex and just matched all my path and port settings exactly. There are a couple of extra mappings required in the docker if im not mistaken but im at work right now and can't look to see what they are. As long as you point to the right place for the app folder and set your media mappings correctly, you should be fine. I started the docker and everything was just there. The only cleanup I had to do was after it was running for a while I had duplicate server entries in PlexPy.
-
I only had one PC to test it with and that is my main desktop. I do not have an extra slot in my unraid server and didn't really want to introduce it if I wasn't sure it was working. I am returning it to the seller and bought another one from another vendor on ebay. Hopefully the 2nd one is good. Is there a set guide to do this process? I found several different sets of steps here and everyone seems to do it a little differently.





