dirrtyjoe
-
Posts
202 -
Joined
-
Last visited
dirrtyjoe's Achievements
")
Explorer (4/14)
1
Reputation
-
 dirrtyjoe changed their profile photo
dirrtyjoe changed their profile photo -
Fix Common Problems has stated I have MCE error(s). My logs are attached. I believe it is due to inadvertently plugging in incompatible memory which has since been fixed but I wanted to post to get some feedback and make sure. Thanks in advance. juggernaut-diagnostics-20180321-1021 (1).zip
-
unRAID OS version 6.4.0 Stable Release Available
dirrtyjoe replied to limetech's topic in Announcements
Found it in the settings. -
unRAID OS version 6.4.0 Stable Release Available
dirrtyjoe replied to limetech's topic in Announcements
How do you start on a different port? I was using 8008 and webui started on 80. -
Thanks, Johnnie.black. I found this: https://www.supermicro.com/support/faqs/faq.cfm?faq=17906 and investigating my setup, I did have VT-d enabled. I've disabled and upon reboot it appears that the error has gone away. I will keep an eye on it and if it persists... probably take your advice and ignore :-) since I'm looking for a "reason" to need to upgrade, anyway.
-
Hey everyone, Just upgraded to 6.3.5 and received the "call traces" error. Can someone take a look at the attached diagnostics to help me identify what may be the problem? Thanks! juggernaut-diagnostics-20170531-0844.zip
-
[Support] Linuxserver.io - Plex Requests
dirrtyjoe replied to linuxserver.io's topic in Docker Containers
Plans to rebrand this to Ombi since Plex asked the original project to remove association with Plex? http://www.ombi.io/ -
I'll add a +1
-
To explicitly respond to your message, is this related to the log file sizes (the reason I have the Userscript piece to my above comment)? I don't believe spants installs the cron automatically so if you forgot to do that piece (or overlooked it) the logs may simply be getting too big.
-
I moved to diginc's repo as it is "directly" tied to the pi-hole development (https://hub.docker.com/r/diginc/pi-hole/). I took spants' template, changed the repository to: 'diginc/pi-hole:alpine' and the docker hub URL to: 'https://hub.docker.com/r/diginc/pi-hole/'. diginc added a parameter to meet the necessary changes that urged spants to create his container, which is disabling IPV6 support so if you add a new container variable: Name: Key 4 Key: IPv6 Value: False Default Value: False you should be up and running as spants designed but using the container that follows the pi-hole development a bit closer. Been running for a few weeks and haven't had an issue. One other thing I did was install the User Scripts plugin and then create the cron script in: /boot/config/plugins/user.scripts/scripts/pihole/ (following the plugin structure, the script is named 'script'). Then I edit the UserScript settings to run it at the interval of my choosing (each morning). My script looks like (just converted the cron file): #!/bin/bash DOCKER_NAME=pihole PATH=/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin # Download any updates from the adlists docker exec $DOCKER_NAME pihole updateGravity > /dev/null # Pi-hole: Update the Web interface shortly after gravity runs # This should also update the version number if it is changed in the dashboard repo #docker exec $DOCKER_NAME pihole updateDashboard > /dev/null # Pi-hole: Parse the log file before it is flushed and save the stats to a database # This will be used for a historical view of your Pi-hole's performance #docker exec $DOCKER_NAME dailyLog.sh # note: this is outdated > /dev/null # Pi-hole: Flush the log daily at 11:58 so it doesn't get out of control # Stats will be viewable in the Web interface thanks to the cron job above docker exec $DOCKER_NAME pihole flush > /dev/null
-
Does adding the .cron file to the plugin directory automatically install/run it?
-
I took that approach. I like the dashboard and logging so I'll keep it! Thanks! But... I'm receiving the following error when trying to add to the whitelist from the web interface: ==> /var/log/nginx/error.log <== 2016/08/30 20:02:04 [error] 239#239: *21 FastCGI sent in stderr: "PHP message: PHP Warning: error_log(/var/log/lighttpd/pihole_php.log): failed to open stream: No such file or directory in /var/www/html/admin/php/add.php on line 3" while reading response header from upstream, client: 192.168.1.206, server: , request: "POST /admin/php/add.php HTTP/1.1", upstream: "fastcgi://127.0.0.1:9000", host: "192.168.1.188", referrer: "http://192.168.1.188/admin/list.php?l=white" Any idea why I'm running into this or how to resolve it?
-
Is it worth using this over your unRAID-hole container?
-
Cache Drive Failing? Trying to remove from Cache pool.
dirrtyjoe replied to dirrtyjoe's topic in General Support
As for how to approach correcting it, any suggestions? Wipe the cache drives, reformat, and start over? -
Cache Drive Failing? Trying to remove from Cache pool.
dirrtyjoe replied to dirrtyjoe's topic in General Support
Adding some detail - the balance seems to be never ending. I see: Jul 27 11:30:58 Juggernaut kernel: BTRFS info (device sdc1): found 1 extents Jul 27 11:30:59 Juggernaut kernel: BTRFS info (device sdc1): found 1 extents Jul 27 11:30:59 Juggernaut kernel: BTRFS info (device sdc1): found 1 extents Jul 27 11:31:00 Juggernaut kernel: BTRFS info (device sdc1): found 1 extents Jul 27 11:31:00 Juggernaut kernel: BTRFS info (device sdc1): found 1 extents Jul 27 11:31:00 Juggernaut kernel: BTRFS info (device sdc1): found 1 extents goes on and on - several times per second. Screenshot with drive labels attached.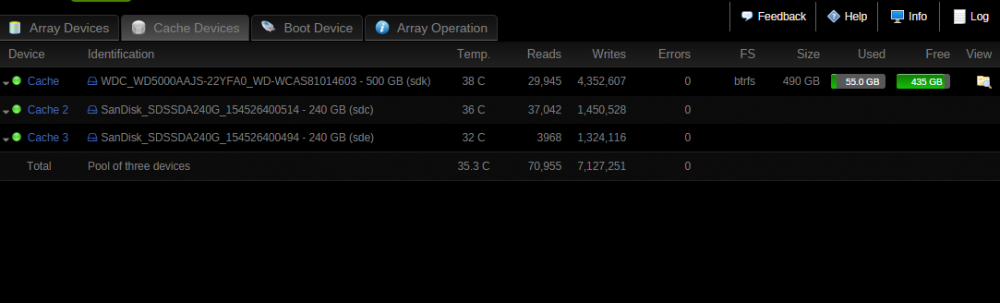
-
It appears my main cache drive is failing. This is a HDD where the other two are SSD so I had planned on removing it anyway. The instructions for removing a drive from a cache pool are numerous and each a bit different. But my goal was to do something like this: [*]Balance Cache [*]Backup Cache Drive [*]Stop the array using the webUI [*]Remove drive to the cache pool [*]Disconnect power/sata from removed drive [*]Start the array [*]Wait for the updated pool to rebalance which will also delete from the pool The initial balance process seems to be hung(?) at: 21 out of about 57 chunks balanced (22 considered), 63% left Any insight into how to handle this? Diagnostics attached. [edit] file too big, apparently... here is a download link: https://1drv.ms/u/s!AlrZB2zl8cavgcso3gs6TsVTgw7dvQ