

dAigo
-
Posts
108 -
Joined
-
Last visited
dAigo's Achievements
")
Apprentice (3/14)
4
Reputation
-
No issues in 6.7.2. Existing VMs (Server 2016) with hyper-v enabled won't boot after update -> stuck at TianoCore Logo Booting into recovery mode works, booting from a install DVD to load virtio drivers and modifiy the bcd works. Removing "hypervisorlaunchtype auto" from bcd makes the VM boot (but disables hyper-v) How to reproduce: (in my case, I hope its not just me ...) 1) new VM with Server 2016 Template 2) Install Server 2016/2019 3) enable hyper-v and reboot. It should either not reboot, boot into recovery or come back with a non working "VMbus" Device in Device manager. Testet with cpu paththrough (default) and cpu emulation (skylake-client), i440fx (default) and q35. Coreinfo.exe always shows vmx and ept present in windows. (see screenshot)) Tried to add vmx explicitly without any change, but as far as windows goes, its always enabled. <feature policy='require' name='vmx'/> Without kvm_intel active, the unraid-server notices it and says it should be enabled. # lsmod | grep kvm kvm_intel 196608 8 kvm 380928 1 kvm_intel I did not get the chance to test 6.8.0 and could not find a link/archive. I would test 6.8.0 to see if that qemu/libvirt version works. Installing hyper-v creates a "VMbus" device in windows, that is not working if you remove "hypervisorlaunchtype auto" from bcd. I think qemu also uses a "VMbus" device to make Windows VM compatibility easier. Maybe thats part of the "Hyper-V" option in the unraid templates? Have not tried other hypervisors or windows 10 hyper-v. As far as kernel options go, "iommu=pt" is a needed workaround for the cheap marvell controller. I'll try to to install the next server in english for better screenshots unraid-diagnostics-20200301-1112.zip
-
I cannot get nested hyper-v to work in 6.8.2, while everything is woking in 6.7.2. Anybody using nested Hyper-V VMs with 6.8.2? (Possibly even running a Skylake CPU) Should I start a Bugreport (incl. diagnostics) or did I just miss anything obvious? Existing VMs with hyper-v enabled won't boot (stuck at TianoCore) Removing "hypervisorlaunchtype auto" from bcd makes the VM boot (but disables hyper-v) Brand new VMs (default Server 2016 template) get stuck after the reboot to enable Hyper-V. Should be easy to reproduce if it was a general problem. Just install server 2016/2019, enable hyper-v and reboot. Testet with cpu paththrough (default) and cpu emulation (skylake-client), i440fx (default) and q35. coreinfo.exe always shows vmx and ept present in windows.
-
I did not follow Betas or RCs, but from the Post that was linked on page 1, it looks, those that were effected changed controllers. Disabling VTd is not an option for me, so it won't help. I am not saying it should or can be fixed, but a note that this has happened so some people may be helpful. And if you follow the link to the bugreport, it was changed to a specific controller. It matches my controller and not those that have no issues. summary: - amd_iommu conflict with Marvell Sata controller + amd_iommu conflict with Marvell 88SE9230 SATA Controller https://bugs.launchpad.net/ubuntu/+source/linux/+bug/1810239 [1b4b:9230] 02:00.0 SATA controller: Marvell Technology Group Ltd. 88SE9230 PCIe SATA 6Gb/s Controller (rev 11) Yes, I knew that before I tried it. I had no issues until 6.7.0. I don't mind, just feedback for those that might also have that exact model.
-
Same issue here, during boot it tried to access the drives but eventually gave up. Havent tried anythig that could change something, like a diffrent PCI-Slot or ACS override. Reroll worked. Agree on having a note in this thread or the release notes. It seems this is a known "potential" issue since RC and has not been fixed for those that are effected. IOMMU group 1: [8086:1901] 00:01.0 PCI bridge: Intel Corporation Xeon E3-1200 v5/E3-1500 v5/6th Gen Core Processor PCIe Controller (x16) (rev 07) [8086:1905] 00:01.1 PCI bridge: Intel Corporation Xeon E3-1200 v5/E3-1500 v5/6th Gen Core Processor PCIe Controller (x8) (rev 07) [1b4b:9230] 02:00.0 SATA controller: Marvell Technology Group Ltd. 88SE9230 PCIe SATA 6Gb/s Controller (rev 11)
-
unRAID Server Release 6.2 Stable Release Available
dAigo replied to limetech's topic in Announcements
I am currently looking into vlans in unraid. I could not find any detailed discussion/explanation, so i'll ask here. http://blog.davidvassallo.me/2012/05/05/kvm-brctl-in-linux-bringing-vlans-to-the-guests/ From what i can see, LT went the first route, because I can see multiple sub-interfaces on eth0 when enabling VLANs. So you could send tagged traffic out, but the returning traffic won't be tagged anymore and, unless defined as PVID/native vlan, therefore ignored by the application inside your VM. If you need ONE inteface in your VM with MANY vlans you would need to add every br0.X interface to the VM and build a bridge in the VM. (packets still wouldn't be tagged) IF kvm would be the main reason for adding/using vlan (in my case it is...) the second way would be far better. I think you could still use br0.X if your vm can't handle vlans (windows vm...). I was looking into pfsense, vmware and other "vlan-aware" applications, but from what I see, that won't work? I am not sure what a change from the current system would mean for other vlan use-cases or even normal usage, maybe it could get changed without harm? Could I still disable vlans in the gui and manually add vlans to the bridge, or does it actually disable any vlan-functionallity? If it was already discussed, i missed the party, sry I could open another thread if you want to keep the anouncement clean -
NVMe GUI integration - Partition format & SMART Info
dAigo replied to dAigo's topic in General Support
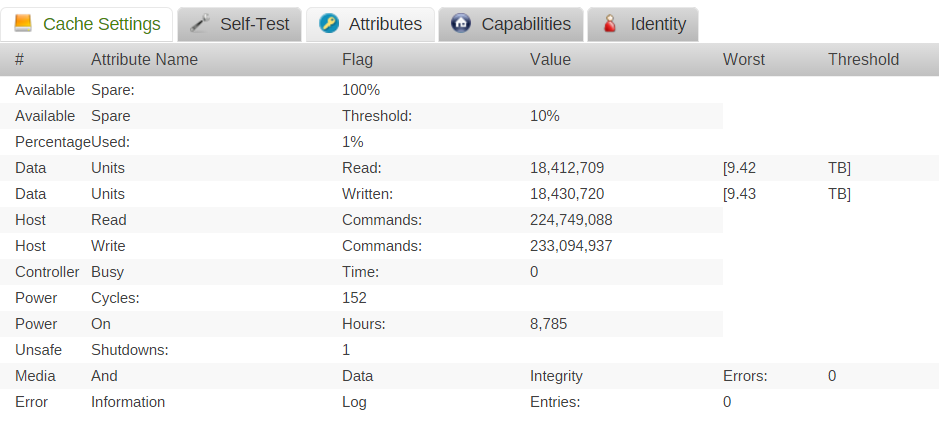
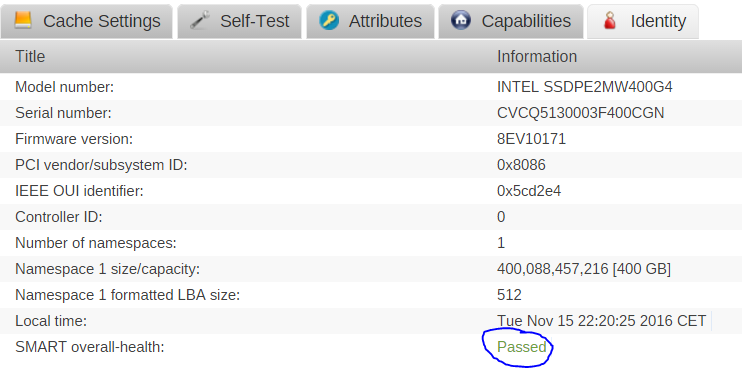
Thats why I said "don't ask me why" it works I am under the same impression as you are. Maybe its a smartmontools bug (experimental after all) but clearly nvm0 gives correct results in regard of the nvme-logs that are specified in the official specs. Currently the GUI ALWAYS states "Unavailable - disk must be spun up" under "Last SMART Results". But I am writng this on a vm thats running on the cache disk, so its NOT spun down. That also changed with nvm0, but the buttons for smart tests were still greyed out. I am not sure, that nvme devices even works the same as old devices. It was designed for flash memory, so most of the old SMART mechanics are useless, because sectors and read/write operations are handled differently. Not sure a "Self Test" makes sense on a flash drive due to that reason... why running a self test, if the specs makes it mandatory to log every error in a log? As long as there is free "Spare" space on the disk, "bad/worn out" flash cells should be "replaced". Same result, nothing changed as far as I can see. root@unRAID:~# smartctl -a -d nvme /dev/nvme0n1 smartctl 6.5 2016-05-07 r4318 [x86_64-linux-4.4.30-unRAID] (local build) Copyright (C) 2002-16, Bruce Allen, Christian Franke, www.smartmontools.org === START OF INFORMATION SECTION === Model Number: INTEL SSDPE2MW400G4 Serial Number: CVCQ5130003F400CGN Firmware Version: 8EV10171 PCI Vendor/Subsystem ID: 0x8086 IEEE OUI Identifier: 0x5cd2e4 Controller ID: 0 Number of Namespaces: 1 Namespace 1 Size/Capacity: 400,088,457,216 [400 GB] Namespace 1 Formatted LBA Size: 512 Local Time is: Wed Nov 16 07:06:07 2016 CET Firmware Updates (0x02): 1 Slot Optional Admin Commands (0x0006): Format Frmw_DL Optional NVM Commands (0x0006): Wr_Unc DS_Mngmt Maximum Data Transfer Size: 32 Pages Supported Power States St Op Max Active Idle RL RT WL WT Ent_Lat Ex_Lat 0 + 25.00W - - 0 0 0 0 0 0 Supported LBA Sizes (NSID 0x1) Id Fmt Data Metadt Rel_Perf 0 + 512 0 2 1 - 512 8 2 2 - 512 16 2 3 - 4096 0 0 4 - 4096 8 0 5 - 4096 64 0 6 - 4096 128 0 === START OF SMART DATA SECTION === Read NVMe SMART/Health Information failed: NVMe Status 0x02 root@unRAID:~# smartctl -a -d nvme /dev/nvme0 smartctl 6.5 2016-05-07 r4318 [x86_64-linux-4.4.30-unRAID] (local build) Copyright (C) 2002-16, Bruce Allen, Christian Franke, www.smartmontools.org === START OF INFORMATION SECTION === Model Number: INTEL SSDPE2MW400G4 Serial Number: CVCQ5130003F400CGN Firmware Version: 8EV10171 PCI Vendor/Subsystem ID: 0x8086 IEEE OUI Identifier: 0x5cd2e4 Controller ID: 0 Number of Namespaces: 1 Namespace 1 Size/Capacity: 400,088,457,216 [400 GB] Namespace 1 Formatted LBA Size: 512 Local Time is: Wed Nov 16 07:06:11 2016 CET Firmware Updates (0x02): 1 Slot Optional Admin Commands (0x0006): Format Frmw_DL Optional NVM Commands (0x0006): Wr_Unc DS_Mngmt Maximum Data Transfer Size: 32 Pages Supported Power States St Op Max Active Idle RL RT WL WT Ent_Lat Ex_Lat 0 + 25.00W - - 0 0 0 0 0 0 Supported LBA Sizes (NSID 0x1) Id Fmt Data Metadt Rel_Perf 0 + 512 0 2 1 - 512 8 2 2 - 512 16 2 3 - 4096 0 0 4 - 4096 8 0 5 - 4096 64 0 6 - 4096 128 0 === START OF SMART DATA SECTION === SMART overall-health self-assessment test result: PASSED SMART/Health Information (NVMe Log 0x02, NSID 0xffffffff) Critical Warning: 0x00 Temperature: 23 Celsius Available Spare: 100% Available Spare Threshold: 10% Percentage Used: 1% Data Units Read: 18,416,807 [9.42 TB] Data Units Written: 18,433,008 [9.43 TB] Host Read Commands: 224,801,960 Host Write Commands: 233,126,889 Controller Busy Time: 0 Power Cycles: 152 Power On Hours: 8,794 Unsafe Shutdowns: 1 Media and Data Integrity Errors: 0 Error Information Log Entries: 0 Error Information (NVMe Log 0x01, max 64 entries) Num ErrCount SQId CmdId Status PELoc LBA NSID VS 0 2 1 - 0x400c - 0 - - 1 1 1 - 0x400c - 0 - - -
NVMe GUI integration - Partition format & SMART Info
dAigo replied to dAigo's topic in General Support
I almost forgot: "Print vendor specific NVMe log pages" is on the list auf 6.6 smartmontools. Not sure if the vendors will find a common way, but at least for current Intel NVMe SSDs, there is a nice reference: Intel® Solid-State Drive DC P3700 Series Specifications (Page 26) -
Partition format: GUI shows "Partition format: unknown", while it should be "GPT: 4K-aligned". SMART Info Back in 6.2 Beta 18, unRAID started support for NVMe devices as cache/pool-disk. Beta 22 got the latest version of smartmontools (6.5) While the CLI output of smartctl definitly improved, GUI still has no SMART info. Which is ok, for an "experimental feature". It even gives errors in the console, while browsing through the Disk-Info of the GUI, which was reported HERE, but got no answer it seems. I have not seen any hint in the 6.3 notes, so I asume, nothing will change. Probably low priority. I think the issue is a wrong smartctl command issued through the WebGUI. In my case, the NVMe disk is the cache disk and the gui identifies it as "nvme0n1", which is not wrong, but does not work with smartmontools... root@unRAID:~# smartctl -x /dev/nvme0n1 smartctl 6.5 2016-05-07 r4318 [x86_64-linux-4.4.30-unRAID] (local build) Copyright (C) 2002-16, Bruce Allen, Christian Franke, www.smartmontools.org === START OF INFORMATION SECTION === Model Number: INTEL SSDPE2MW400G4 Serial Number: CVCQ5130003F400CGN Firmware Version: 8EV10171 PCI Vendor/Subsystem ID: 0x8086 IEEE OUI Identifier: 0x5cd2e4 Controller ID: 0 Number of Namespaces: 1 Namespace 1 Size/Capacity: 400,088,457,216 [400 GB] Namespace 1 Formatted LBA Size: 512 Local Time is: Tue Nov 15 20:21:12 2016 CET Firmware Updates (0x02): 1 Slot Optional Admin Commands (0x0006): Format Frmw_DL Optional NVM Commands (0x0006): Wr_Unc DS_Mngmt Maximum Data Transfer Size: 32 Pages Supported Power States St Op Max Active Idle RL RT WL WT Ent_Lat Ex_Lat 0 + 25.00W - - 0 0 0 0 0 0 Supported LBA Sizes (NSID 0x1) Id Fmt Data Metadt Rel_Perf 0 + 512 0 2 1 - 512 8 2 2 - 512 16 2 3 - 4096 0 0 4 - 4096 8 0 5 - 4096 64 0 6 - 4096 128 0 === START OF SMART DATA SECTION === Read NVMe SMART/Health Information failed: NVMe Status 0x02 Don't ask me why, but if you use the "NVMe character device (ex: /dev/nvme0)" instead of the "namespace block device (ex: /dev/nvme0n1)" there is a lot more information. Like "SMART overall-health self-assessment test result: PASSED" root@unRAID:~# smartctl -x /dev/nvme0 smartctl 6.5 2016-05-07 r4318 [x86_64-linux-4.4.30-unRAID] (local build) Copyright (C) 2002-16, Bruce Allen, Christian Franke, www.smartmontools.org === START OF INFORMATION SECTION === Model Number: INTEL SSDPE2MW400G4 Serial Number: CVCQ5130003F400CGN Firmware Version: 8EV10171 PCI Vendor/Subsystem ID: 0x8086 IEEE OUI Identifier: 0x5cd2e4 Controller ID: 0 Number of Namespaces: 1 Namespace 1 Size/Capacity: 400,088,457,216 [400 GB] Namespace 1 Formatted LBA Size: 512 Local Time is: Tue Nov 15 20:37:58 2016 CET Firmware Updates (0x02): 1 Slot Optional Admin Commands (0x0006): Format Frmw_DL Optional NVM Commands (0x0006): Wr_Unc DS_Mngmt Maximum Data Transfer Size: 32 Pages Supported Power States St Op Max Active Idle RL RT WL WT Ent_Lat Ex_Lat 0 + 25.00W - - 0 0 0 0 0 0 Supported LBA Sizes (NSID 0x1) Id Fmt Data Metadt Rel_Perf 0 + 512 0 2 1 - 512 8 2 2 - 512 16 2 3 - 4096 0 0 4 - 4096 8 0 5 - 4096 64 0 6 - 4096 128 0 === START OF SMART DATA SECTION === SMART overall-health self-assessment test result: PASSED SMART/Health Information (NVMe Log 0x02, NSID 0xffffffff) Critical Warning: 0x00 Temperature: 24 Celsius Available Spare: 100% Available Spare Threshold: 10% Percentage Used: 1% Data Units Read: 18,412,666 [9.42 TB] Data Units Written: 18,429,957 [9.43 TB] Host Read Commands: 224,748,225 Host Write Commands: 233,072,991 Controller Busy Time: 0 Power Cycles: 152 Power On Hours: 8,784 Unsafe Shutdowns: 1 Media and Data Integrity Errors: 0 Error Information Log Entries: 0 Error Information (NVMe Log 0x01, max 64 entries) Num ErrCount SQId CmdId Status PELoc LBA NSID VS 0 2 1 - 0x400c - 0 - - 1 1 1 - 0x400c - 0 - - According to NVME Specs (Page 92-94) the output does contain all "mandatory" information. (so it "should work" regardless of the vendor...) Its probably a PITA, but I guess there are not many common information between SATA/IDE and NVMe Smart Infos... which means the GUI needs some reworking in that regard. I guess "SMART overall-health self-assessment test result", "Critical Warning", "Media and Data Integrity Errors" and "Error Information Log Entries" would be most usefull in terms of health info and things that could raise an alert/notification. Depending on the amount of work it needs, maybe monitoring "Spare Threshold" as an indication of a "soon to fail" drive (like reallocated events/sectors). For science: I changed the "$port" variable in "smartinfo.php" to a hardcoded "nvme0", ignoring any POST values. See attachments for the result... not that bad for the quickest and most dirty solution I could think of unraid-smart-20161115-2020.zip unraid-smart-20161115-2220_with_nvme0.zip
-
Curious how many others have had this as an issue before... I definitly had issues in the past, stopping the array without manually shutting down VMs/Docker. (once the array stopped, I never had issues though) If I remember correctly, it was a thing in 6.1. Spinning up all disks and shutting down every VM and Container one by one, has become a habit. I think the "stop Array" did not work, when I was logged into the console and had the prompt somewhere in the array (/mnt/user/...). The web-gui was not responding until the array was stopped, which never happened, so I could not restart the array or cleanly shut down the server. I couldn't even tell in which state the VMs/container were, so at first I thought the VMs/Container were causing the issue. And because of the 6.2 (beta) issues with the complete array lockdown ("num_stripes"), I still do it as a precaution. So, if anything happens after I press "stop array", at least I know there is no VM/container running/shutting down that could be the issue. The system usually runs 24/7, so it's not a big deal, but since you asked... Due to that habit, I can't tell if its still an issue or not. That beeing said, no issues in 6.2.4 that I can speak of I had a system freeze due to an GPU-overclock attempt and fat-fingering a '9' instead of '0'... The unclean shutdown was correctly recognized, parity check started, 9 errors corrected with normal speed. That did not happen during beta array-lockups and may have been a result of the fixes 6.2.3.
-
I choose to use the Plugin "Open Files" to do the job. Find the entry that locks the .vhdx file and you are fine. cleanest way would be to disconnect the disk through windows before you reboot, but you are probably as lazy as I am ;-)
-
Well, as it was said, it worked due to a bug. I actually have not tried any other version than RC3, but that one worked. Maybe that bug was only present in the kernel used in 6.2 RC3... or maybe not even every Skylake board is affected. There is a workaround which more or less reproduce the effects of the bug. (not beeing able to load a module) If you blacklist the driver, that prevents any device in the iommu grp to be passed through, it seems to be working. I have not yet seen any side effects, but since I do not 100% know what that device does, its on your own risk Go to "Main" -> "Boot Device" -> "Flash" -> "Syslinux configuration" Add "modprobe.blacklist=i2c_i801,i2c_smbus" somewhere between "append" and "initrd=/bzroot". It should look like this: label unRAID OS menu default kernel /bzimage append modprobe.blacklist=i2c_i801,i2c_smbus initrd=/bzroot Then save and reboot and see if you can start the VM with the onboard sound attached. If not, you should post a diagnostics (tools -> diagnostics) or at least tell us what the iommu grps look like. (tools -> sytem devices) Even if it works, keep in mind its a workaround, not a solution. A solution would probably to buy an additional pci-soundcard and pass that through. There is a chance, that Intel just broke the passthrough of the onboard sound by grouping it up with another device. Maybe intentional, to push virtualisation to their workstation/Server hardware... or its an ASUS thing, because we both have ASUS.
-
Right for iGPU, wrong for audio... due to a bug in older kernels, it worked although it should not have due to the iommu grps. Go HERE for Details... Its just RC4 that does this, due to its newer kernel. Go with RC3 until they fix it... There are several ways to fix this, I think they are looking for the best way.
-
How to create a VM with no Local LAN or Host Access, but has Internet ?
dAigo replied to Pducharme's topic in VM Engine (KVM)
Like I said, the description of virbr0 suggests, that there is no firewall in place, just NAT (Network Adress Translation). So, your VM is placed "behind" your server in a diffrent subnet, like your LAN is placed behind your router. Your router has a firewall, unraid does not. Adding a firewall to the virbr0 could be another solution. There are many things that wont work through NAT. Like browsing the network, which is reliant on broadcasts and netbios. If you disable the firewall on the other server and try to PING its IP-Adress (not hostname) it should work. But you are still releativly "safe" because unless someone knows your real LAN and its ip-adresses, they would not know where to start. Malware however could just scan any private network and would eventually find your LAN and its devices and could do whatever it would do if it was in the same network. In fact, I just looked into it, and it seems iptables is already running and active, to provide the docker network with everything it needs... (so the wiki is inacurate ) I asume the following rule is in place for the virbr0 network: Chain FORWARD (policy ACCEPT) target prot opt source destination ACCEPT all -- anywhere 192.168.122.0/24 ctstate RELATED,ESTABLISHED ACCEPT all -- 192.168.122.0/24 anywhere Which means the private network is allowed to go anywhere and all data that was requested from inside is allowed to go there. I am very rusty with iptables, but if you add a DENY rule for your LAN, in front of the second rule that allows all, everything in your LAN should be "safe"... To access this a VM with virbr0 from the internet (like rdp), would also require to add/modify itaples rules. If anyone is interested, I would suggest the libvirt-wiki: -
How to create a VM with no Local LAN or Host Access, but has Internet ?
dAigo replied to Pducharme's topic in VM Engine (KVM)
Or, very quick, cheap and probably dirty... You could use a firewall on the VM (windows fw may already do the trick). Just block all of your internal IP-Addresses for outgoing and incoming traffic, except your router. As long as you make sure, that your guests cannot alter these firewall-rules (no admin!), it should be "safe". You could even consider using RemoteApps instead of a full blown Remote-Desktop. That is possible even with a normal Windows: RemoteApp-Tool Your possibilitys depend on your available hardware (router/switch) outside of unraid, if you post them, somebody may help with a more specific answer. -
How to create a VM with no Local LAN or Host Access, but has Internet ?
dAigo replied to Pducharme's topic in VM Engine (KVM)
It states: He writes: And it seems to be NAT that "prevents" access from LAN->VM not a firewall. I do not know the specific configuration, but usually, VM->LAN should still work, so the VM could access unriad and other ressources on the LAN, just not the other way around (without specific ports forwarded to the VM). Unless the private bridge/kvm has some sort of firewall that can and does block traffic, in which case, access to the host maybe could be blocked as well. I guess to be 100% sure, he would need to create a second subnet/VLAN on his router (wich is not a normal feature for consumer stuff, custom firmware may be needed) and either use VLANs or a diffrent physical port on the router and unraid. Or buy a second router/firewall basicly do the same. Or create a second VM, a router/firewall like pfsense, and declare that as the default GW for his vm. He could block all traffic from his vm to his LAN on that gateway. Or, if his router has wifi with a guest SSID, he may try to passthrough a (USB/PCI) WiFi-card to the VM and use the guest SSID, wich should be isolated...


