

landS
-
Posts
822 -
Joined
-
Last visited





landS's Achievements
")
Collaborator (7/14)
17
Reputation
-
My rig is located on a high shelf in our bedroom closet which is limited on depth. Swapping out Internal disk’s requires getting it down with a ladder with little maneuver space and this is too brutal on my permanently injured back and knee. …. I am swapping out my 40# Fractal Design’s R4 Silent (18.27" x 9.13" x 20.59") for a unit with front hot-swap bays. I’m also going from 8 4TB drives to 2 20TB drives. This rig has 2 GPU’s in it for 2 separate VMs, 1 Full Size ODD, and an ATX Mobo (X10SRA-F). …. While not 5.25 bays top to bottom, this may help someone out: 18# InWin IW-PE689 (18.1" x 7.9" x 16.9"). … Has 4 External 5.25 bays and 1 External 3.5 bay. Icy Dock MB155SP-B 5x3.5 (3x5.25” bay) with a Noctua NF-B9 Icy Dock MB741SP-B 1x2.5 (1x3.5” bay) SilverStone Technology EPDM Sound Dampening Foam
-
Thanks itimpi! I rather like the option for disk fault tolerance, and also think the backup is a good idea. I'll stick to 1 parity and 1 pre-cleared spare. I have a second unraid server with no exported network shares that I turn on quarterly and run 2 backup scripts: For write once, never change: rsync -r -v --progress --ignore-existing -s /mnt/disks/TOWER_WriteOnce/WriteOnce/ /mnt/user/Media/WriteOnce For write many: rsync -av --progress --delete-before /mnt/disks/TOWER_WriteMany/WriteMany /mnt/user/WriteMany In addition, I run the Crashplan Docker on folders containing important data.
-
Strange question for you goodly folks. Is there any benefit to using 2 Parity Disks with 1 Data Disk? My array is comprised of 5 data disks and 2 parity drives - all 4 TB with an average power on time of around 7 years. I am replacing these with 3 20 TB disks: 2 Seagate IronWolf Pro CMR & 1 WD Red Pro CMR If no benefit to using 2 Parity Disks with 1 Data Disk, I will keep 1 of the disks as a pre-cleared hot-spare. Thanks!
-

[Support] Djoss - CrashPlan PRO (aka CrashPlan for Small Business)
landS replied to Djoss's topic in Docker Containers
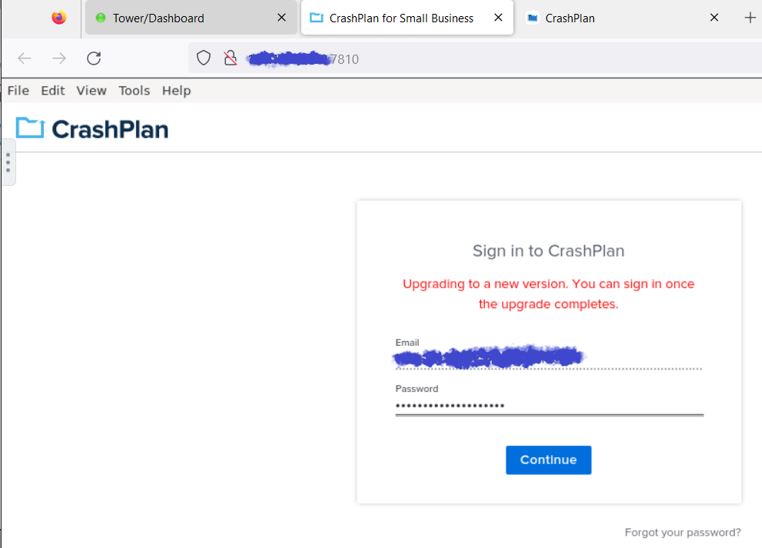
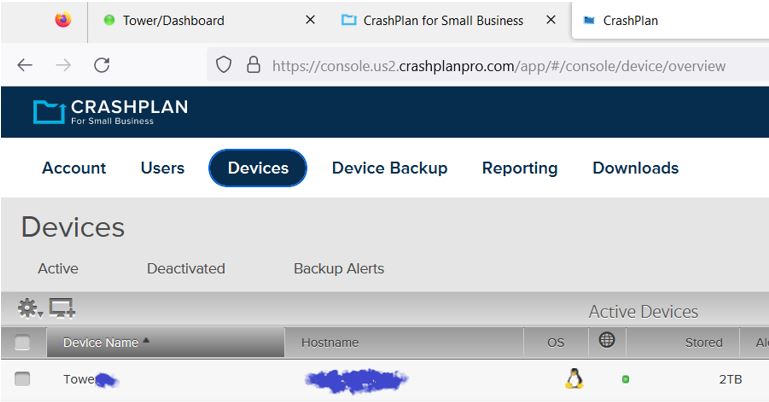
Alas, this appears to be a troublesome beast. I updated from v6.12.1 to 6.12.2. In the Crashplan Docker’s WebUi it shows in the left hand popout: Crashplan v11.1.1 & Docker Image v23.06.2 Image 1 is what the Crashplan WebUi looks like when I start the docker. Image 2 is what the Crashplan WebUi looks like after I insert the password and click Continue. This is where the message pops up. If I close the WebUi and open it up the problem persists. Image 3 is what Crashplan’s Website looks like. The only item of note here is that the computer shows as online.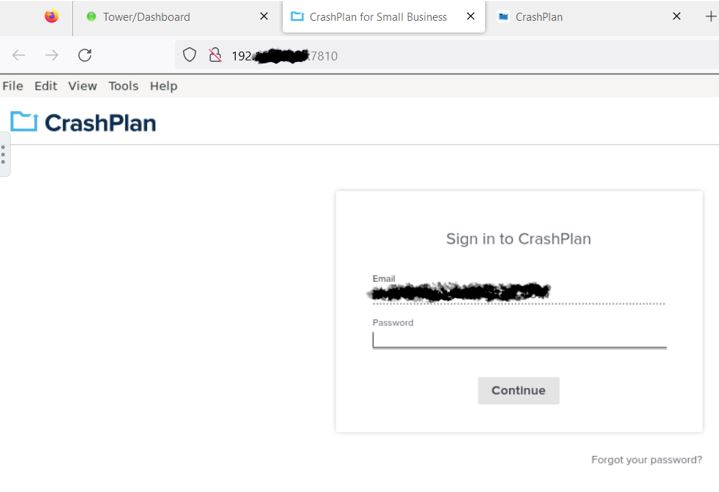
-
[Support] Djoss - CrashPlan PRO (aka CrashPlan for Small Business)
landS replied to Djoss's topic in Docker Containers
Thanks for the quick turn-around Djoss. Alas no, Docker's WebGui Still shows the "upgrading to new version" message after entering login credentials into Web Gui's Interface. Edit after 3 hours: Docker's WebGui still throws the "upgrading to new version" issue Docker's WebGui shows version 11.1.1.2 CP's Website Portal indicates Computer is Online & Backup is 100% CP's Website Portal shows version 11.1.1.2 -
[Support] Djoss - CrashPlan PRO (aka CrashPlan for Small Business)
landS replied to Djoss's topic in Docker Containers
Howdy folks, Since updating to 6.12 from 6.11 I've been having the same issue as @Gico: I can't login the web-ui saying Crashplan is "upgrading to a new version" -
Howdy Folks! I'm in need of some help. Part 1 ---------------- Typical behavior & problem Typically when storms are coming through I go into the Web Gui, stop the docker, stop the virtual machines, stop the array, and only then power down. The Web Gui always comes back up after the server is powered back on. Last night a storm came in while I was away and the server shutdown via UPS due to an extended power outage. After reboot I can access dockers, VMs, network shares – but not the Web Gui Part 2 ---------------- Troubleshooting Via a IPMI KVM Redirect I can access the terminal. Running the following immediately allows access to the Web Gui: … /etc/rc.d/rc.docker stop … /etc/rc.d/rc.php-fpm restart From this point: … Diagnostics obtained (tower-diagnostics-20230507-0856) … Stopping the VM worked fine … Stopping the Array did not – stuck with /mnt/cache: target is busy – retry unmounting disk share(s) – “Log Snippet” at bottom of post … After about 15 minutes of this I then pressed power off in web gui … Part 3 ---------------- Power back on after step 2 Web Gui is accessible from Windows Os only after boot & an automatic parity check was initiated which is atypical (tower-diagnostics-20230507-0916) I only use http://###.###.#.###/Main to access the GUI – Chrome or Firefox browsers I can now fully access it via a Windows PC (had to dust this off) I can no longer access it via Android or Linux device on same network (which is all we really use here) I typically only access via Android … Part 4 ---------------- Questions 1 – What can I do so that this behavior doesn’t happen again? 2 – How can I make the Web Gui Accessible via a non-Windows device again? Thanks folks! … … … … Log snippet from part 3 above: May 7 08:58:33 Tower emhttpd: Stopping services... May 7 08:58:33 Tower emhttpd: shcmd (116): /etc/rc.d/rc.libvirt stop May 7 08:58:33 Tower root: Stopping libvirtd... May 7 08:58:33 Tower dnsmasq[7063]: exiting on receipt of SIGTERM May 7 08:58:33 Tower avahi-daemon[5931]: Interface virbr0.IPv4 no longer relevant for mDNS. May 7 08:58:33 Tower avahi-daemon[5931]: Leaving mDNS multicast group on interface virbr0.IPv4 with address 192.168.122.1. May 7 08:58:33 Tower avahi-daemon[5931]: Withdrawing address record for 192.168.122.1 on virbr0. May 7 08:58:33 Tower root: Network a4007147-6d28-4b27-8a73-0b1a1672c02b destroyed May 7 08:58:33 Tower root: May 7 08:58:37 Tower root: Stopping virtlogd... May 7 08:58:38 Tower root: Stopping virtlockd... May 7 08:58:39 Tower emhttpd: shcmd (117): umount /etc/libvirt May 7 08:58:39 Tower cache_dirs: Stopping cache_dirs process 5345 May 7 08:58:40 Tower cache_dirs: cache_dirs service rc.cachedirs: Stopped May 7 08:58:40 Tower Recycle Bin: Stopping Recycle Bin May 7 08:58:40 Tower emhttpd: Stopping Recycle Bin... May 7 08:58:40 Tower emhttpd: shcmd (119): /etc/rc.d/rc.samba stop May 7 08:58:40 Tower wsdd2[7683]: 'Terminated' signal received. May 7 08:58:40 Tower wsdd2[7683]: terminating. May 7 08:58:40 Tower emhttpd: shcmd (120): rm -f /etc/avahi/services/smb.service May 7 08:58:40 Tower avahi-daemon[5931]: Files changed, reloading. May 7 08:58:40 Tower avahi-daemon[5931]: Service group file /services/smb.service vanished, removing services. May 7 08:58:40 Tower emhttpd: shcmd (122): /etc/rc.d/rc.nfsd stop May 7 08:58:40 Tower rpc.mountd[4443]: Caught signal 15, un-registering and exiting. May 7 08:58:41 Tower emhttpd: Stopping mover... May 7 08:58:41 Tower emhttpd: shcmd (123): /usr/local/sbin/mover stop May 7 08:58:41 Tower kernel: nfsd: last server has exited, flushing export cache May 7 08:58:41 Tower root: mover: not running May 7 08:58:41 Tower emhttpd: Sync filesystems... May 7 08:58:41 Tower emhttpd: shcmd (124): sync May 7 08:58:41 Tower emhttpd: shcmd (125): umount /mnt/user0 May 7 08:58:41 Tower emhttpd: shcmd (126): rmdir /mnt/user0 May 7 08:58:41 Tower emhttpd: shcmd (127): umount /mnt/user May 7 08:58:43 Tower emhttpd: shcmd (128): rmdir /mnt/user May 7 08:58:43 Tower emhttpd: shcmd (130): /usr/local/sbin/update_cron May 7 08:58:43 Tower emhttpd: Unmounting disks... May 7 08:58:43 Tower emhttpd: shcmd (131): umount /mnt/disk1 … May 7 08:58:45 Tower emhttpd: shcmd (141): umount /mnt/cache May 7 08:58:45 Tower root: umount: /mnt/cache: target is busy. May 7 08:58:45 Tower emhttpd: shcmd (141): exit status: 32 May 7 08:58:45 Tower emhttpd: Retry unmounting disk share(s)... tower-diagnostics-20230507-0916.zip tower-diagnostics-20230507-0856.zip
-
Good point JonathanM. Our AC runs 9 months a year... with a setting of 78*F. I believe it highly likely I'll need to replace 2 of the drives in the next 2 years: $140. Yearly Energy Savings over the next 2 years: $210 (lowered HDD power + 9 months of AC) Likely near term Cost savings: $350. That makes the decision, not a $700 one, but a $350. Mhh... is $350 worth: Reset of the bathtub curve / peace of mind Reduced Noise It very well might be.
-
Thanks CharNoir. I mainly wanted a sanity check on the electrical cost savings --- another set of eyes to see if what I’ve stated appears correct. Saving $60/year at a cost of $700 certainly doesn’t make economical sense. Paying $700 now when I could replace an occasional drive for $70 also doesn’t make economical sense. However, a lot of my drives in my main machine are reaching the 10+ year powered-on mark and the backside of the bathtub appears to be coming into play. As such I need to weigh: Cost Savings Reset of the bathtub curve / peace of mind Reduced Noise (this is in my master bedrooms closet) Reduced Heat
-
Howdy folks, My server has 7 OLD 4TB 7200 drives (2 parity/5 data) for 20TB of storage. These do not spin down due to my using crashplan (on about 3 Tb worth of the data). I estimate that these consume about 8 watts each. I believe I can reduce the array to 2 disks by moving to 2 20TB disks (1 parity /1 data) which would save 40 watts…. I believe this works out to be 350 kWh over the course of a year. My utility company charges $0.173/kWh (and climbing)… so by moving from 7 4TB drives to 2 20TB drives I’d save a whopping $60/year. Does this math look about right to you folks --- or am I missing something glaring here? A CMR SATA Seagate IronWolf Pro or Exos X20 look to go for $350 new - and $700 is a heck of a lot more than the occasional replacement cost of $70. Beyond saving electric costs - the server is in my bedroom closet & reducing noise would be nice. Also it would be nice to reset the long-int-the-tooth drives. Thanks!
-
6.11.1 Windows 10 Steam Failing due to 'fatal stalled cross-thread pipe'
landS replied to landS's topic in VM Engine (KVM)
for anyone else experiencing this 1 - you'll find folks running on linux versions - including SteamOS having this very issue. 2 - switching the client to Beta fixes the issue. -
Sorry about that Kizer! Work went nutso and this fell off my radar. I ended up powering down all networked electronics - and since rebooting each the gremlin hasn't poked up it's head. I'll toss a diagnostics up if it happens again.
-
Howdy Folks, Since updating to 6.11.1 my Windows 10 VM's Steam Client is failing every 10-15 minutes. The Steam dump message is 'fatal stalled cross-thread pipe' Has anyone come across this & if so know how to remediate? Thanks!
-
Howdy folks, Anytime my Windows Work machine is turned on - on same network - Im getting CONSTANT logging showing: Oct 15 14:59:27 Tower nginx: 2022/10/15 14:59:27 [error] 4424#4424: *2478717 limiting requests, excess: 20.122 by zone "authlimit", client: (Redacted Work PC IP number), server: , request: "PROPFIND /login HTTP/1.1", host: "tower" Any ideas on how to remediate this? Thanks!
-
Most of my 4tb HGST drives are 'Manufacturer Recertified'. I figure if they pass a few preclears, they are well past early bathtub failure, and any gremlins should have reared up. I've had a couple fail that check.



