Leaderboard




Popular Content
Showing content with the highest reputation on 07/27/17 in all areas
-
Not sure if this was requested previously or not. Can we have the ability to... 1. Control the order in which containers and VMs start as one or more may have dependencies on others 2. Add a delay value to when a container or VM starts Make sense? Maybe it could be bundled with the request here which is kinda related: http://lime-technology.com/forum/index.php?topic=40537.0 John1 point
-
I just wanted to take a minute and thank the creators and dedicated forum members of this amazing software. I purchased an Unraid license 5 years ago and my array has grown from 3 drives/6TB to 9 drives/41TB with nothing but mostly smooth sailing. Well last night I had my first disk error and after a single read/write error Unraid automatically took that disk offline to prevent any data loss and went into emulated mode. Now it just so happened to be my most crucial disk because it had 10 years of irreplaceable data on it (tax records, work documents, wedding photos, computer backups, etc.) but luckily I had enough free space available on my array and I was able to easily transfer all 2.8TB of data to another disk without losing a single byte. So I just wanted to say thank you to everyone involved for creating such an amazing piece of software that is extremely easy to use and makes it so I can sleep soundly at night not worrying about losing any data. Easily the best $50 I've ever spent!1 point
-
The UPS will work fine without communicating with unraid. However... if you are not able to shut down the server before the battery runs down, unraid doesn't know it's supposed to shut down and you will be faced with a parity check on startup at the very least, and possible data corruption. Why do you not want to set it up so unraid can manage a controlled shutdown? BTW, I would never recommend purposely running a UPS below 50% capacity, ideally you should be shutting down with about 75% battery left, so you don't wear out the battery so quickly. UPS batteries last longer if you don't drain them fully, and it takes a significant amount of time to recharge them after an event. If your events typically don't last more than a minute, then set unraid to shut down after 3 minutes on battery. It will take a few minutes to get everything shut down anyway.1 point
-
OK, well that helps. Files created by windows are as i7quad:users and existing permissions on the files you're having issues with are RWX for nobody R_X for the users, R_X for everyone else. Now as both your Windows machine and your Syncthing files are owned by the same group, essentially it means your Windows box can read and execute files just not write. I can't really help with the next bit, but as I see it, you have two options. 1. Try and find a way to make your existing files RWX for the group, thus allowing Windows to write 2. Get Windows to access the files as nobody:users rather than i7quad:users Unfortunately I'm not sure how to do either of those, Syncthing forum would be a good place to look regarding option 1. For option 2, that will be something to do with Windows and not something I have a clue about to be honest, but you're definitely on the right track now we've isolated the issue.1 point
-
So, I don't know jack about windows smb permissions, but the owner & group look fine. If Windows can RW files by nobody:users you should be good as on insugent you have 644 as a perm and parent directory is 744.1 point
-
Still can't say, but the key is you need to start looking at the file permissions and identify what they actually are. It might be inheriting them from the seedbox? Once you work out what the file permissions/owner/group are then it makes identifing the cause easier.1 point
-
PUID and PGID are the parameters in the template to set ownership. I use Syncthing myself and have no issues, and on Unraid PUID and PGID shouldn't need to be changed at all, as essentially it make the owner of files nobody:users which is the same as Unraid's default. But without more details on your setup it's impossible to say any more really.1 point
-
Ok now that the crash is fixed, I've added support for video discs in the watch folder. New image will be available in couple of minutes!1 point
-
There's still filesystem corruption on disk2 (md2), run xfs_repair again, and make sure it's not running in read only mode (-n)1 point
-
Well gents, just wanted to give you a update on Ryzen w/ c-states enabled locking up unRAID... or rather how we've fixed it! On my Ryzen test machine, with array stopped (to keep it idle) with c-states enabled in bios, I'm approaching 7 days of uptime. Before the changes we made to the kernel in the upcoming RC7, It would only make it a few hours and lockup. I think you guys will find RC7 just epyc! (sorry, couldn't resist) FYI, these are the two kernel changes we had to add to make it stable for Ryzen: - CONFIG_RCU_NOCB_CPU: Offload RCU callback processing from boot-selected CPUs - CONFIG_RCU_NOCB_CPU_ALL: All CPUs are build_forced no-CBs CPUs Thanks to everyone here for testing and helping narrow it down to c-states. That made it easier for us to test and find a solution.1 point
-
1 point
-
Ok, so the issue has been identified. It is a problem with fping, the author has merged two fping binaries into one, fping and fping6. However despite running with a parameter to use only fping on IPV4 it fails on any system that doesn't have IPV6 enabled in the kernel. A bug report has already been filed, but as yet hasn't been fixed. So the fix is to produce a specific build of smokeping ONLY for Unraid users on v6.3.x as v6.4 has IPV6 enabled so is not affected, hence why we couldn't reproduce it. To pull this build edit your docker config and change the repository from linuxserver/smokeping to linuxserver/smokeping:unraid Now, I'll be the first to admit, things have got a little tense on this thread recently and I think this highlights some of the difficulties we face at ls.io. We're volunteers and using our spare time. This error hasn't been introduced by us changing the docker code at all, but by upstream changes. Now, you could argue that we could produce a static build that is never updated and would work forever, the problem with that approach is one of security, the reason we run weekly updates is to grab any upstream patches to mitigate this. After all we have seen some impressive security vulnerabilities in the Linux world over the last few years. So I don't think this is a reasonable course of action. If one of our containers was "unpatched" and you were hit with a vulnerability, I'm guessing you wouldn't be impressed..... This issue has been multifactorial Update in fping No IPV6 in Unraid v6.3.x Docker update So I'm not prepared to take full responsibility for this, we do our best with limited resources of time and personnel to do what we do, if you want to use our stuff, then feel free, but understand your use of our containers doesn't constitute a contract of support. Compare it to Ubuntu, if you want support, you pay for a support contract, the software itself is free. We don't have support contracts, nor do we intend to ever charge for support, however if you're reliant in some way on a container in a "mission critical" sense then I would suggest looking elsewhere, forking and maintaining it yourself, or hiring an IT professional to support your needs. I don't intend to stir up feelings again, but I've had some time to reflect on things and these are the conclusions I've come to. This is free software from fping, smokeping, alpine, linuxserver. None of us are getting paid, none of us have any obligations, and any of us could disappear overnight without any repercussions on ourselves, the use of free software is open and I applaud it and embrace it, but the use of free software has to be recognised to be different to that of using something like Microsoft Windows, where you buy a product, and have a clear expectation as the buyer that it should work as expected. The benefit of free software is all the source code is open and visible, so anybody could have identified the issue, including the end users, as indicated by the fping bug report. Bottom line, with as many repos as we have, and with a huge number of upstream projects we're using, we can't physically investigate everything with the number of people we have and the time we have available. If you want to help, great, come and chat to us, we're crying out for people to help with dev, support and infrastructure, the only requirement is a willingness to learn and the ability to get on with people along with some devotion of your free time.1 point
-
There has been a DMCA done by echel0n (because he says its his code as had the first fork lol when its midgetspys and open source!) which is causing an error on the general tab A work around is to clone a mirror into the container. Make sure the sickrage container is running then ssh into your unraid server using putty if PC or terminal if Mac then run docker exec -it binhex-sickrage /bin/bash That will get us into the shell of the Docker container. This container is based on Arch Linux and with need to install git so now run this command pacman -S git Say yes to proceed with the installation. After this has installed we need to delete the current sickrage in the container rm -r /opt/sickrage now we need to pull down sickrage from the mirror with this command git clone https://distortion.io/git/mirror/sickrage.git /opt/sickrage All done so now stop the container and restart and you will be good to go
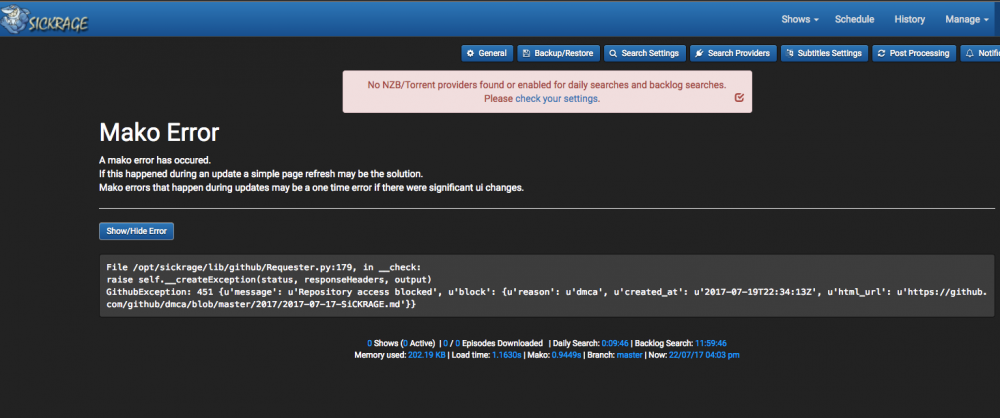 1 point
1 point -
Quick new update for the website part of the app. However, so as to not overwrite people's existing advanced.yaml settings, normal app updates do not replace the appdata config files that you may have customized. So after updating the docker, to get the changes please temporarily copy your appdata folder contents to a different location. Then restart the docker which will place the new files into your appdata directory. You can then copy back in your advanced.yaml file. If you have any questions, let me know. Thanks. CHANGES: - Updated links to HTTPS for those that run it on SSL, your cert should show as fully secure now. Thanks to @naturalcarr for the suggestion. - Updated Web page links to open in a new page. Thanks to @dcpdad for the suggestion.1 point
-
Could you also attach the file '/config/ghb/Activity.log.*'? Which preset are you using?1 point




