Leaderboard




Popular Content
Showing content with the highest reputation on 03/21/17 in all areas
-
Turbo Write technically known as "reconstruct write" - a new method for updating parity JonP gave a short description of what "reconstruct write" is, but I thought I would give a little more detail, what it is, how it compares with the traditional method, and the ramifications of using it. First, where is the setting? Go to Settings -> Disk Settings, and look for Tunable (md_write_method). The 3 options are read/modify/write (the way we've always done it), reconstruct write (Turbo write, the new way), and Auto which is something for the future but is currently the same as the old way. To change it, click on the option you want, then the Apply button. The effect should be immediate. Traditionally, unRAID has used the "read/modify/write" method to update parity, to keep parity correct for all data drives. Say you have a block of data to write to a drive in your array, and naturally you want parity to be updated too. In order to know how to update parity for that block, you have to know what is the difference between this new block of data and the existing block of data currently on the drive. So you start by reading in the existing block, and comparing it with the new block. That allows you to figure out what is different, so now you know what changes you need to make to the parity block, but first you need to read in the existing parity block. So you apply the changes you figured out to the parity block, resulting in a new parity block to be written out. Now you want to write out the new data block, and the parity block, but the drive head is just past the end of the blocks because you just read them. So you have to wait a long time (in computer time) for the disk platters to rotate all the way back around, until they are positioned to write to that same block. That platter rotation time is the part that makes this method take so long. It's the main reason why parity writes are so much slower than regular writes. To summarize, for the "read/modify/write" method, you need to: * read in the parity block and read in the existing data block (can be done simultaneously) * compare the data blocks, then use the difference to change the parity block to produce a new parity block (very short) * wait for platter rotation (very long!) * write out the parity block and write out the data block (can be done simultaneously) That's 2 reads, a calc, a long wait, and 2 writes. Turbo write is the new method, often called "reconstruct write". We start with that same block of new data to be saved, but this time we don't care about the existing data or the existing parity block. So we can immediately write out the data block, but how do we know what the parity block should be? We issue a read of the same block on all of the *other* data drives, and once we have them, we combine all of them plus our new data block to give us the new parity block, which we then write out! Done! To summarize, for the "reconstruct write" method, you need to: * write out the data block while simultaneously reading in the data blocks of all other data drives * calculate the new parity block from all of the data blocks, including the new one (very short) * write out the parity block That's a write and a bunch of simultaneous reads, a calc, and a write, but no platter rotation wait! Now you can see why it can be so much faster! The upside is it can be much faster. The downside is that ALL of the array drives must be spinning, because they ALL are involved in EVERY write. So what are the ramifications of this? * For some operations, like parity checks and parity builds and drive rebuilds, it doesn't matter, because all of the drives are spinning anyway. * For large write operations, like large transfers to the array, it can make a big difference in speed! * For a small write, especially at an odd time when the drives are normally sleeping, all of the drives have to be spun up before the small write can proceed. * And what about those little writes that go on in the background, like file system housekeeping operations? EVERY write at any time forces EVERY array drive to spin up. So you are likely to be surprised at odd times when checking on your array, and expecting all of your drives to be spun down, and finding every one of them spun up, for no discernible reason. * So one of the questions to be faced is, how do you want your various write operations to be handled. Take a small scheduled backup of your phone at 4 in the morning. The backup tool determines there's a new picture to back up, so tries to write it to your unRAID server. If you are using the old method, the data drive and the parity drive have to spin up, then this small amount of data is written, possibly taking a couple more seconds than Turbo write would take. It's 4am, do you care? If you were using Turbo write, then all of the drives will spin up, which probably takes somewhat longer spinning them up than any time saved by using Turbo write to save that picture (but a couple of seconds faster in the save). Plus, all of the drives are now spinning, uselessly. * Another possible problem if you were in Turbo mode, and you are watching a movie streaming to your player, then a write kicks in to the server and starts spinning up ALL of the drives, causing that well-known pause and stuttering in your movie. Who wants to deal with the whining that starts then? Currently, you only have the option to use the old method or the new (currently the Auto option means the old method). But the plan is to add the true Auto option that will use the old method by default, *unless* all of the drives are currently spinning. If the drives are all spinning, then it slips into Turbo. This should be enough for many users. It would normally use the old method, but if you planned a large transfer or a bunch of writes, then you would spin up all of the drives - and enjoy faster writing. Tom talked about that Auto mode quite awhile ago, but I'm rather sure he backed off at that time, once he faced the problems of knowing when a drive is spinning, and being able to detect it without noticeably affecting write performance, ruining the very benefits we were trying to achieve. If on every write you have to query each drive for its status, then you will noticeably impact I/O performance. So to maintain good performance, you need another function working in the background keeping near-instantaneous track of spin status, and providing a single flag for the writer to check, whether they are all spun up or not, to know which method to use. So that provides 3 options, but many of us are going to want tighter and smarter control of when it is in either mode. Quite awhile ago, WeeboTech developed his own scheme of scheduling. If I remember right (and I could have it backwards), he was going to use cron to toggle it twice a day, so that it used one method during the day, and the other method at night. I think many users may find that scheduling it may satisfy their needs, Turbo when there's lots of writing, old style over night and when they are streaming movies. For awhile, I did think that other users, including myself, would be happiest with a Turbo button on the Main screen (and Dashboard). Then I realized that that's exactly what our Spin up button would be, if we used the new Auto mode. The server would normally be in the old mode (except for times when all drives were spinning). If we had a big update session, backing up or or downloading lots of stuff, we would click the Turbo / Spin up button and would have Turbo write, which would then automatically timeout when the drives started spinning down, after the backup session or transfers are complete. Edit: added what the setting is and where it's located (completely forgot this!)1 point
-
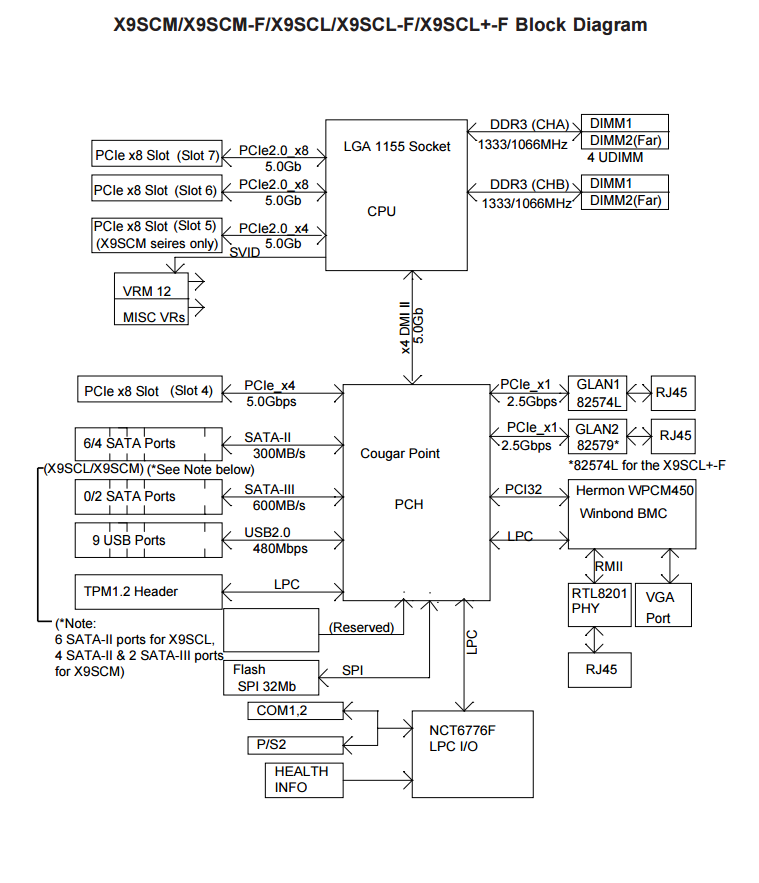
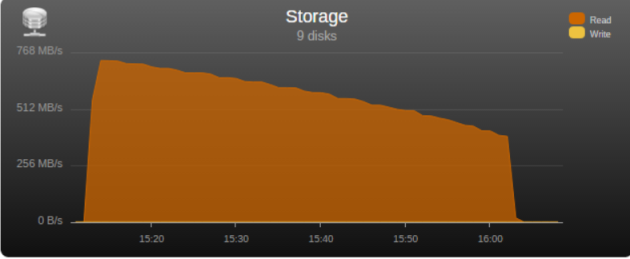
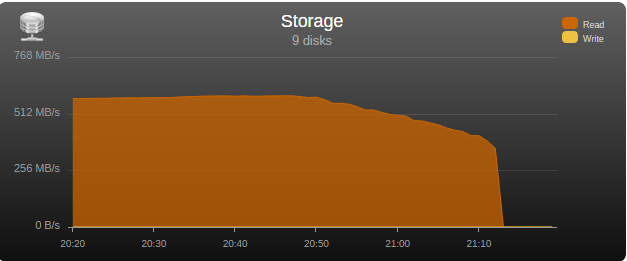
I had the opportunity to test the “real word” bandwidth of some commonly used controllers in the community, so I’m posting my results in the hopes that it may help some users choose a controller and others understand what may be limiting their parity check/sync speed. Note that these tests are only relevant for those operations, normal read/writes to the array are usually limited by hard disk or network speed. Next to each controller is its maximum theoretical throughput and my results depending on the number of disks connected, result is observed parity/read check speed using a fast SSD only array with Unraid V6 Values in green are the measured controller power consumption with all ports in use. 2 Port Controllers SIL 3132 PCIe gen1 x1 (250MB/s) 1 x 125MB/s 2 x 80MB/s Asmedia ASM1061 PCIe gen2 x1 (500MB/s) - e.g., SYBA SY-PEX40039 and other similar cards 1 x 375MB/s 2 x 206MB/s JMicron JMB582 PCIe gen3 x1 (985MB/s) - e.g., SYBA SI-PEX40148 and other similar cards 1 x 570MB/s 2 x 450MB/s 4 Port Controllers SIL 3114 PCI (133MB/s) 1 x 105MB/s 2 x 63.5MB/s 3 x 42.5MB/s 4 x 32MB/s Adaptec AAR-1430SA PCIe gen1 x4 (1000MB/s) 4 x 210MB/s Marvell 9215 PCIe gen2 x1 (500MB/s) - 2w - e.g., SYBA SI-PEX40064 and other similar cards (possible issues with virtualization) 2 x 200MB/s 3 x 140MB/s 4 x 100MB/s Marvell 9230 PCIe gen2 x2 (1000MB/s) - 2w - e.g., SYBA SI-PEX40057 and other similar cards (possible issues with virtualization) 2 x 375MB/s 3 x 255MB/s 4 x 204MB/s IBM H1110 PCIe gen2 x4 (2000MB/s) - LSI 2004 chipset, results should be the same as for an LSI 9211-4i and other similar controllers 2 x 570MB/s 3 x 500MB/s 4 x 375MB/s Asmedia ASM1064 PCIe gen3 x1 (985MB/s) - e.g., SYBA SI-PEX40156 and other similar cards 2 x 450MB/s 3 x 300MB/s 4 x 225MB/s Asmedia ASM1164 PCIe gen3 x2 (1970MB/s) - NOTE - not actually tested, performance inferred from the ASM1166 with up to 4 devices 2 x 565MB/s 3 x 565MB/s 4 x 445MB/s 5 and 6 Port Controllers JMicron JMB585 PCIe gen3 x2 (1970MB/s) - 2w - e.g., SYBA SI-PEX40139 and other similar cards 2 x 570MB/s 3 x 565MB/s 4 x 440MB/s 5 x 350MB/s Asmedia ASM1166 PCIe gen3 x2 (1970MB/s) - 2w 2 x 565MB/s 3 x 565MB/s 4 x 445MB/s 5 x 355MB/s 6 x 300MB/s 8 Port Controllers Supermicro AOC-SAT2-MV8 PCI-X (1067MB/s) 4 x 220MB/s (167MB/s*) 5 x 177.5MB/s (135MB/s*) 6 x 147.5MB/s (115MB/s*) 7 x 127MB/s (97MB/s*) 8 x 112MB/s (84MB/s*) * PCI-X 100Mhz slot (800MB/S) Supermicro AOC-SASLP-MV8 PCIe gen1 x4 (1000MB/s) - 6w 4 x 140MB/s 5 x 117MB/s 6 x 105MB/s 7 x 90MB/s 8 x 80MB/s Supermicro AOC-SAS2LP-MV8 PCIe gen2 x8 (4000MB/s) - 6w 4 x 340MB/s 6 x 345MB/s 8 x 320MB/s (205MB/s*, 200MB/s**) * PCIe gen2 x4 (2000MB/s) ** PCIe gen1 x8 (2000MB/s) LSI 9211-8i PCIe gen2 x8 (4000MB/s) - 6w – LSI 2008 chipset 4 x 565MB/s 6 x 465MB/s 8 x 330MB/s (190MB/s*, 185MB/s**) * PCIe gen2 x4 (2000MB/s) ** PCIe gen1 x8 (2000MB/s) LSI 9207-8i PCIe gen3 x8 (4800MB/s) - 9w - LSI 2308 chipset 8 x 565MB/s LSI 9300-8i PCIe gen3 x8 (4800MB/s with the SATA3 devices used for this test) - LSI 3008 chipset 8 x 565MB/s (425MB/s*, 380MB/s**) * PCIe gen3 x4 (3940MB/s) ** PCIe gen2 x8 (4000MB/s) SAS Expanders HP 6Gb (3Gb SATA) SAS Expander - 11w Single Link with LSI 9211-8i (1200MB/s*) 8 x 137.5MB/s 12 x 92.5MB/s 16 x 70MB/s 20 x 55MB/s 24 x 47.5MB/s Dual Link with LSI 9211-8i (2400MB/s*) 12 x 182.5MB/s 16 x 140MB/s 20 x 110MB/s 24 x 95MB/s * Half 6GB bandwidth because it only links @ 3Gb with SATA disks Intel® SAS2 Expander RES2SV240 - 10w Single Link with LSI 9211-8i (2400MB/s) 8 x 275MB/s 12 x 185MB/s 16 x 140MB/s (112MB/s*) 20 x 110MB/s (92MB/s*) * Avoid using slower linking speed disks with expanders, as it will bring total speed down, in this example 4 of the SSDs were SATA2, instead of all SATA3. Dual Link with LSI 9211-8i (4000MB/s) 12 x 235MB/s 16 x 185MB/s Dual Link with LSI 9207-8i (4800MB/s) 16 x 275MB/s LSI SAS3 expander (included on a Supermicro BPN-SAS3-826EL1 backplane) Single Link with LSI 9300-8i (tested with SATA3 devices, max usable bandwidth would be 2200MB/s, but with LSI's Databolt technology we can get almost SAS3 speeds) 8 x 500MB/s 12 x 340MB/s Dual Link with LSI 9300-8i (*) 10 x 510MB/s 12 x 460MB/s * tested with SATA3 devices, max usable bandwidth would be 4400MB/s, but with LSI's Databolt technology we can closer to SAS3 speeds, with SAS3 devices limit here would be the PCIe link, which should be around 6600-7000MB/s usable. HP 12G SAS3 EXPANDER (761879-001) Single Link with LSI 9300-8i (2400MB/s*) 8 x 270MB/s 12 x 180MB/s 16 x 135MB/s 20 x 110MB/s 24 x 90MB/s Dual Link with LSI 9300-8i (4800MB/s*) 10 x 420MB/s 12 x 360MB/s 16 x 270MB/s 20 x 220MB/s 24 x 180MB/s * tested with SATA3 devices, no Databolt or equivalent technology, at least not with an LSI HBA, with SAS3 devices limit here would be the around 4400MB/s with single link, and the PCIe slot with dual link, which should be around 6600-7000MB/s usable. Intel® SAS3 Expander RES3TV360 Single Link with LSI 9308-8i (*) 8 x 490MB/s 12 x 330MB/s 16 x 245MB/s 20 x 170MB/s 24 x 130MB/s 28 x 105MB/s Dual Link with LSI 9308-8i (*) 12 x 505MB/s 16 x 380MB/s 20 x 300MB/s 24 x 230MB/s 28 x 195MB/s * tested with SATA3 devices, PMC expander chip includes similar functionality to LSI's Databolt, with SAS3 devices limit here would be the around 4400MB/s with single link, and the PCIe slot with dual link, which should be around 6600-7000MB/s usable. Note: these results were after updating the expander firmware to latest available at this time (B057), it was noticeably slower with the older firmware that came with it. Sata 2 vs Sata 3 I see many times on the forum users asking if changing to Sata 3 controllers or disks would improve their speed, Sata 2 has enough bandwidth (between 265 and 275MB/s according to my tests) for the fastest disks currently on the market, if buying a new board or controller you should buy sata 3 for the future, but except for SSD use there’s no gain in changing your Sata 2 setup to Sata 3. Single vs. Dual Channel RAM In arrays with many disks, and especially with low “horsepower” CPUs, memory bandwidth can also have a big effect on parity check speed, obviously this will only make a difference if you’re not hitting a controller bottleneck, two examples with 24 drive arrays: Asus A88X-M PLUS with AMD A4-6300 dual core @ 3.7Ghz Single Channel – 99.1MB/s Dual Channel - 132.9MB/s Supermicro X9SCL-F with Intel G1620 dual core @ 2.7Ghz Single Channel – 131.8MB/s Dual Channel – 184.0MB/s DMI There is another bus that can be a bottleneck for Intel based boards, much more so than Sata 2, the DMI that connects the south bridge or PCH to the CPU. Socket 775, 1156 and 1366 use DMI 1.0, socket 1155, 1150 and 2011 use DMI 2.0, socket 1151 uses DMI 3.0 DMI 1.0 (1000MB/s) 4 x 180MB/s 5 x 140MB/s 6 x 120MB/s 8 x 100MB/s 10 x 85MB/s DMI 2.0 (2000MB/s) 4 x 270MB/s (Sata2 limit) 6 x 240MB/s 8 x 195MB/s 9 x 170MB/s 10 x 145MB/s 12 x 115MB/s 14 x 110MB/s DMI 3.0 (3940MB/s) 6 x 330MB/s (Onboard SATA only*) 10 X 297.5MB/s 12 x 250MB/s 16 X 185MB/s *Despite being DMI 3.0** , Skylake, Kaby Lake, Coffee Lake, Comet Lake and Alder Lake chipsets have a max combined bandwidth of approximately 2GB/s for the onboard SATA ports. **Except low end H110 and H310 chipsets which are only DMI 2.0, Z690 is DMI 4.0 and not yet tested by me, but except same result as the other Alder Lake chipsets. DMI 1.0 can be a bottleneck using only the onboard Sata ports, DMI 2.0 can limit users with all onboard ports used plus an additional controller onboard or on a PCIe slot that shares the DMI bus, in most home market boards only the graphics slot connects directly to CPU, all other slots go through the DMI (more top of the line boards, usually with SLI support, have at least 2 slots), server boards usually have 2 or 3 slots connected directly to the CPU, you should always use these slots first. You can see below the diagram for my X9SCL-F test server board, for the DMI 2.0 tests I used the 6 onboard ports plus one Adaptec 1430SA on PCIe slot 4. UMI (2000MB/s) - Used on most AMD APUs, equivalent to intel DMI 2.0 6 x 203MB/s 7 x 173MB/s 8 x 152MB/s Ryzen link - PCIe 3.0 x4 (3940MB/s) 6 x 467MB/s (Onboard SATA only) I think there are no big surprises and most results make sense and are in line with what I expected, exception maybe for the SASLP that should have the same bandwidth of the Adaptec 1430SA and is clearly slower, can limit a parity check with only 4 disks. I expect some variations in the results from other users due to different hardware and/or tunnable settings, but would be surprised if there are big differences, reply here if you can get a significant better speed with a specific controller. How to check and improve your parity check speed System Stats from Dynamix V6 Plugins is usually an easy way to find out if a parity check is bus limited, after the check finishes look at the storage graph, on an unlimited system it should start at a higher speed and gradually slow down as it goes to the disks slower inner tracks, on a limited system the graph will be flat at the beginning or totally flat for a worst-case scenario. See screenshots below for examples (arrays with mixed disk sizes will have speed jumps at the end of each one, but principle is the same). If you are not bus limited but still find your speed low, there’s a couple things worth trying: Diskspeed - your parity check speed can’t be faster than your slowest disk, a big advantage of Unraid is the possibility to mix different size disks, but this can lead to have an assortment of disk models and sizes, use this to find your slowest disks and when it’s time to upgrade replace these first. Tunables Tester - on some systems can increase the average speed 10 to 20Mb/s or more, on others makes little or no difference. That’s all I can think of, all suggestions welcome.
 1 point
1 point -
Check filesystem on disk1 (md1) https://lime-technology.com/wiki/index.php/Check_Disk_Filesystems#Drives_formatted_with_XFS1 point
-
Max speed in a x4 slot with 8 disks is 190MB/s, so enough for most disks. https://forums.lime-technology.com/topic/41340-satasas-controllers-tested-real-world-max-throughput-during-parity-check/#comment-4065211 point
-
I'll start by giving some background on the current wiki method, and then touch on a few things you may not have thought about. I had noticed already several users using unBALANCE, and had been thinking about adding a method based on it, but I won't be able to completely flesh out the steps as I've never used unBALANCE, and can't because I don't use User Shares (which of course partly explains my own methodology). I've always preferred knowing and controlling exactly where everything is, and I've a personal catalog file I keep open in an editor tab with all of my series and categories listed, with the drives they're on. For example, I know that my Alias shows are on Disk 1, and all my PBS stuff is on Disk 4. User Shares are convenient for many, but for me it just adds another layer to the access. Off-topic though ... But converting drives is a drive issue, only indirectly a User Share issue. It's drives that are formatted, and that dominates the problem. I don't know for sure, but I suspect if you wrote out the steps for doing the entire array with unBALANCE, it would be close to 19, or maybe even more. A general method for users at large has to handle every contingency and every situational variation, as safely as possible for the least technical of users. That always takes longer, and often more steps are involved, 'just in case'. It inevitably means lots more words! I do think my method is the most straightforward, safest, and fastest though, but then disk shares is what I work with and understand. It does have an extra step or two to accommodate User Shares. For User Share users, which is most or almost all unRAID users, unBALANCE sounds attractive, and I agree that it's a great plugin! It uses basically the same rsync command, so should have the same speed and file verification checksumming for the individual transfers. But in operation over multiple drives, it's likely to take longer, because it's moving the files off one drive to the others, then moving the files back when you do the next drive, and possibly moving some files multiple times, pushing them around the various drives to keep them out of the way of the next format operation. With my method, files only move once. The only way to make sure no files get moved more than once with unBALANCE is to carefully manage exactly where each file starts and where it ends up, and that sounds like something you wanted to avoid, if you don't want to care where the files are. To me, my method seems just as seamless, and allows full operation just as much. Both ways, you have to stop the array, make changes, then restart the array, just as many times. When I did it with 6.1, I didn't have to use New Config, just adjust the assignments and restart the array. Unfortunately in 6.2, something changed and it won't allow that, so we had to add the New Config step, which I agree does add a little extra hassle. 6.0 and 6.1 users don't have to do that. We have requested that to be corrected, so we can just restart the array, but as far as I know, it hasn't happened yet (haven't checked it recently though). The strong cautions though are just as important, for either method! How do you know for sure that there were not files lost when you did it? Because if there were any other processes (internal plugins, Dockers, scheduled scripts, or VM's, or externally scheduled backups) writing files to the array, they could very well have added files to the very drive you were emptying with unBALANCE. In fact, the emptying of a shared drive makes it the most attractive target for writing new files to. Either you make absolutely sure that nothing else could be writing to the array, or you should run unBALANCE a final time, just to make sure that nothing is left on the drive (written to it after unBALANCE had swept across it), before you format it. Does unBALANCE after moving folders come back and check if they have reappeared on that drive, with more files in them? So I'll add a general unBALANCE-based method, and I think many users may prefer it, as it does hide some of the detail, but it will take longer to perform. And they will have to manually configure unBALANCE for each drive emptying. The steps will have to have just as many warnings. Users who aren't running anything else at all will obviously have a simpler time, can ignore the warnings, but that's a special case. I really don't want any of this to be daunting or nerve-wracking, but each time we hear of a user doing something we hadn't thought of and getting into trouble, the word count increases. The more words, the more daunting it appears ... (just look at this post for instance!)1 point
-
I wrote a daemon. I think it's in the rclone thread. It's much more complicated your way, even if it were possible.1 point
-
Hey @jbrodriguez, love the iOS app! I'm trying to install the plugin for the server and I get the following output. Hoping you can help! plugin: installing: https://raw.githubusercontent.com/jbrodriguez/unraid/master/plugins/controlr.plg plugin: downloading https://raw.githubusercontent.com/jbrodriguez/unraid/master/plugins/controlr.plg plugin: downloading: https://raw.githubusercontent.com/jbrodriguez/unraid/master/plugins/controlr.plg ... done Warning: simplexml_load_file(): /tmp/plugins/controlr.plg:69: parser error : xmlParseEntityRef: no name in /usr/local/emhttp/plugins/dynamix.plugin.manager/scripts/plugin on line 214 Warning: simplexml_load_file(): nohup /usr/local/emhttp/plugins/&name;/scripts/start > /dev/null 2>&1 & in /usr/local/emhttp/plugins/dynamix.plugin.manager/scripts/plugin on line 214 Warning: simplexml_load_file(): ^ in /usr/local/emhttp/plugins/dynamix.plugin.manager/scripts/plugin on line 214 Warning: simplexml_load_file(): /tmp/plugins/controlr.plg:69: parser error : xmlParseEntityRef: no name in /usr/local/emhttp/plugins/dynamix.plugin.manager/scripts/plugin on line 214 Warning: simplexml_load_file(): nohup /usr/local/emhttp/plugins/&name;/scripts/start > /dev/null 2>&1 & in /usr/local/emhttp/plugins/dynamix.plugin.manager/scripts/plugin on line 214 Warning: simplexml_load_file(): ^ in /usr/local/emhttp/plugins/dynamix.plugin.manager/scripts/plugin on line 214 Warning: simplexml_load_file(): /tmp/plugins/controlr.plg:69: parser error : xmlParseEntityRef: no name in /usr/local/emhttp/plugins/dynamix.plugin.manager/scripts/plugin on line 214 Warning: simplexml_load_file(): nohup /usr/local/emhttp/plugins/&name;/scripts/start > /dev/null 2>&1 & in /usr/local/emhttp/plugins/dynamix.plugin.manager/scripts/plugin on line 214 Warning: simplexml_load_file(): ^ in /usr/local/emhttp/plugins/dynamix.plugin.manager/scripts/plugin on line 214 Warning: simplexml_load_file(): /tmp/plugins/controlr.plg:69: parser error : xmlParseEntityRef: no name in /usr/local/emhttp/plugins/dynamix.plugin.manager/scripts/plugin on line 214 Warning: simplexml_load_file(): nohup /usr/local/emhttp/plugins/&name;/scripts/start > /dev/null 2>&1 & in /usr/local/emhttp/plugins/dynamix.plugin.manager/scripts/plugin on line 214 Warning: simplexml_load_file(): ^ in /usr/local/emhttp/plugins/dynamix.plugin.manager/scripts/plugin on line 214 Warning: simplexml_load_file(): /tmp/plugins/controlr.plg:69: parser error : xmlParseEntityRef: no name in /usr/local/emhttp/plugins/dynamix.plugin.manager/scripts/plugin on line 214 Warning: simplexml_load_file(): nohup /usr/local/emhttp/plugins/&name;/scripts/start > /dev/null 2>&1 & in /usr/local/emhttp/plugins/dynamix.plugin.manager/scripts/plugin on line 214 Warning: simplexml_load_file(): ^ in /usr/local/emhttp/plugins/dynamix.plugin.manager/scripts/plugin on line 214 Warning: simplexml_load_file(): /tmp/plugins/controlr.plg:69: parser error : xmlParseEntityRef: no name in /usr/local/emhttp/plugins/dynamix.plugin.manager/scripts/plugin on line 214 Warning: simplexml_load_file(): nohup /usr/local/emhttp/plugins/&name;/scripts/start > /dev/null 2>&1 & in /usr/local/emhttp/plugins/dynamix.plugin.manager/scripts/plugin on line 214 Warning: simplexml_load_file(): ^ in /usr/local/emhttp/plugins/dynamix.plugin.manager/scripts/plugin on line 214 plugin: xml parse error1 point
-
I recommend changing that to either 60, 120, or 180 (1, 2, or 3 minutes).1 point